
Apache Solr
Einleitung
In der heutigen datengetriebenen Welt stellt die effiziente Suche in großen, unstrukturierten und semi-strukturierten Datenbeständen eine der größten Herausforderungen für Unternehmen und Organisationen dar. Traditionelle Datenbanksysteme stoßen oft an ihre Grenzen, wenn es darum geht, komplexe Suchanfragen in Echtzeit zu bewältigen oder Millionen von Dokumenten effizient zu durchsuchen. Diese Problematik wird durch die zunehmende Vielfalt an Datenformaten, die exponentielle Zunahme von Datenvolumen und die wachsenden Anforderungen an personalisierte, präzise Suchergebnisse zusätzlich verschärft.
Apache Solr, ein ursprünglich von der Firma CNET entwickelter Open-Source-Suchserver, wurde 2004 erstmals veröffentlicht und später zu einem wichtigen Projekt der Apache Software Foundation. Es wurde speziell entwickelt, um die Herausforderungen der Indexierung und Suche in umfangreichen Datenbeständen zu bewältigen. Solr kombiniert Leistungsfähigkeit mit Flexibilität und ermöglicht nicht nur die Verarbeitung großer Datenmengen, sondern auch die Integration moderner Suchfunktionen wie Facettierung, Geodatenabfragen und Relevanzbewertung. Die Plattform hat sich zu einem unverzichtbaren Werkzeug für Unternehmen aus unterschiedlichsten Branchen entwickelt, darunter E-Commerce, Gesundheitswesen, Medien und Finanzdienstleistungen.
Funktionalität von Apache Solr
Solr bietet eine Vielzahl an leistungsfähigen Funktionen, die es ermöglichen, große Datenmengen effizient zu durchsuchen und zu analysieren. Dabei zeichnet sich das System durch seine hohe Anpassbarkeit und Skalierbarkeitaus. Um die Stärken von Solr besser zu verstehen, werden die wichtigsten technischen Aspekte im Detail betrachtet.
Indexierung und Suche
Eine der zentralen Aufgaben von Solr ist die effiziente Indexierung und Suche in großen Datenbeständen. Solr kann sowohl strukturierte als auch unstrukturierte Daten verarbeiten und unterstützt verschiedene Eingangsformate wie JSON, XML und CSV. Durch den Einsatz der Lucene-Engine ermöglicht Solr eine leistungsfähige Volltextsuche, die verschiedene Suchstrategien wie exakte Übereinstimmungen, Phrasensuche, Wildcard-Suche und unscharfe Suche (Fuzzy Search) unterstützt.
Besonders wichtig ist dabei die Echtzeit-Indexierung. Neue oder aktualisierte Daten stehen sofort für Suchanfragen zur Verfügung, wodurch Solr sich für Anwendungsfälle eignet, bei denen schnelle Datenaktualisierungen erforderlich sind. Zudem können mehrere Indizes parallel verwaltet und kombiniert werden, was eine strukturierte Organisation und flexible Abfragen von Daten ermöglicht.
Facettierung und Aggregation
Ein weiteres zentrales Feature von Solr ist die Facettierung, die es ermöglicht, Suchergebnisse dynamisch zu gruppieren und zu strukturieren. Dabei können verschiedene Facettentypen, wie hierarchische, numerische oder zeitbasierte Facetten, genutzt werden. Dies erleichtert die Organisation großer Datenmengen und verbessert die Nutzererfahrung durch eine intelligente Kategorisierung der Suchergebnisse.
Darüber hinaus unterstützt Solr leistungsfähige Aggregationsfunktionen, mit denen sich statistische Kennwerte direkt innerhalb der Suchanfragen berechnen lassen. Summen, Durchschnittswerte oder Extremwerte können somit ohne externe Verarbeitung ermittelt werden. Dies führt zu einer effizienten Analyse und reduziert den zusätzlichen Rechenaufwand.
Skalierbarkeit und Fehlertoleranz
Ein entscheidender Vorteil von Solr ist seine hervorragende Skalierbarkeit. Durch die Möglichkeit der Sharding-Technologie kann ein Index auf mehrere Teilbereiche (Shards) verteilt werden, wodurch die Suchgeschwindigkeit und Verarbeitungskapazität optimiert werden. Dies ist besonders vorteilhaft für sehr große Datenmengen, die in verteilten Systemen effizient verwaltet werden müssen.
Zusätzlich sorgt das Replikationssystem für eine hohe Fehlertoleranz. Indem Kopien der Shards auf mehreren Knoten gespeichert werden, bleibt das System auch dann funktionsfähig, wenn einzelne Knoten ausfallen. Diese Mechanismen gewährleisten eine hohe Verfügbarkeit und Ausfallsicherheit, was Solr zu einer zuverlässigen Lösung für produktive Umgebungen macht.
Anpassungsfähigkeit und Relevanzbewertung
Solr bietet eine detaillierte Steuerung der Relevanzbewertung, wodurch sich Suchergebnisse gezielt optimieren lassen. Durch gewichtete Felder, Boosting-Parameter und Synonymlisten können die Ergebnisse einer Suchanfrage exakt an die individuellen Anforderungen einer Anwendung angepasst werden.
Ein weiterer wichtiger Aspekt ist die Unterstützung für mehrsprachige Abfragen. Mithilfe von spezialisierten Textanalysefunktionen kann Solr Inhalte in verschiedenen Sprachen analysieren und verarbeiten, wodurch die Suchgenauigkeit verbessert wird. Dies macht Solr zu einer universell einsetzbaren Suchlösung für internationale Anwendungen.
Highlighting
Solr verfügt über eine Highlighting-Funktion, die relevante Textstellen innerhalb der Suchergebnisse visuell hervorhebt. Dies erleichtert die Identifikation der relevantesten Inhalte innerhalb eines Dokuments und verbessert die Nutzbarkeit der Suchfunktion. Die Darstellung kann individuell konfiguriert werden, indem Start- und End-Tags definiert oder verschiedene Highlighting-Methoden angewendet werden.
Geodatenabfragen
Um unautorisierte Zugriffe zu verhindern, bietet Solr eine Reihe von Sicherheitsfunktionen. Dazu gehören Authentifizierungsmechanismen wie Basic Auth oder Kerberos sowie eine detaillierte Zugriffskontrolle auf Index- und Dokumentebene. Zusätzlich unterstützt Solr SSL-Verschlüsselung zur sicheren Übertragung von Daten zwischen Clients und Servern. Diese Sicherheitsmaßnahmen gewährleisten die Integrität und den Schutz sensibler Daten in produktiven Umgebungen.
Sicherheitsfunktionen
Um unautorisierte Zugriffe zu verhindern, bietet Solr eine Reihe von Sicherheitsfunktionen. Dazu gehören Authentifizierungsmechanismen wie Basic Auth oder Kerberos sowie eine detaillierte Zugriffskontrolle auf Index- und Dokumentebene. Zusätzlich unterstützt Solr SSL-Verschlüsselung zur sicheren Übertragung von Daten zwischen Clients und Servern. Diese Sicherheitsmaßnahmen gewährleisten die Integrität und den Schutz sensibler Daten in produktiven Umgebungen.
Integration und Erweiterbarkeit
Solr lässt sich dank seiner RESTful-API problemlos in bestehende Systeme integrieren. Durch die breite Unterstützung von Plugins und Erweiterungen kann die Funktionalität gezielt an spezifische Anforderungen angepasst werden. Zudem bietet Solr Schnittstellen für externe Analysetools und Datenbanken, wodurch es sich nahtlos in bestehende IT-Infrastrukturen einfügt.
Mehrsprachige Unterstützung
Solr bietet Funktionen zur Verarbeitung und Analyse von mehrsprachigen Daten. Durch spezialisierte Sprachmodule können Texte in verschiedenen Sprachen indexiert und durchsucht werden. Diese Module berücksichtigen sprachspezifische Unterschiede, sodass relevante Ergebnisse unabhängig von der verwendeten Sprache geliefert werden.
Terminologie von Apache Solr
Apache Solr besteht aus mehreren Kernkomponenten, die zusammenarbeiten, um eine effiziente Indexierung und Suche zu ermöglichen. Die folgenden Begriffe beschreiben die wesentlichen Bestandteile der Solr-Architektur und deren Funktion innerhalb des Systems.
Node
Ein Node ist eine einzelne Instanz eines Solr-Servers, die auf einem bestimmten Host und Port läuft. Innerhalb eines Nodes können mehrere Cores existieren, die jeweils eigenständige Indizes verwalten. Ein Node kann sowohl Such- als auch Indexierungsanfragen verarbeiten und kommuniziert mit anderen Nodes in einem Cluster.
Cluster
Ein Cluster ist eine Gruppe von Solr-Nodes, die gemeinsam einen verteilten Such- und Indexierungsdienst bereitstellen. Innerhalb eines Clusters werden Daten über mehrere Nodes hinweg verteilt, um Skalierbarkeit und Lastverteilung zu ermöglichen. Die Verwaltung und Koordination der Nodes erfolgt über ZooKeeper.
Core
Ein Core ist eine einzelne Index-Instanz innerhalb eines Solr-Nodes. Jeder Core verfügt über eine eigene Konfiguration, einschließlich Schema-Definitionen und Indexierungsparametern. Innerhalb eines Nodes können mehrere Cores existieren, die unabhängig voneinander betrieben werden.
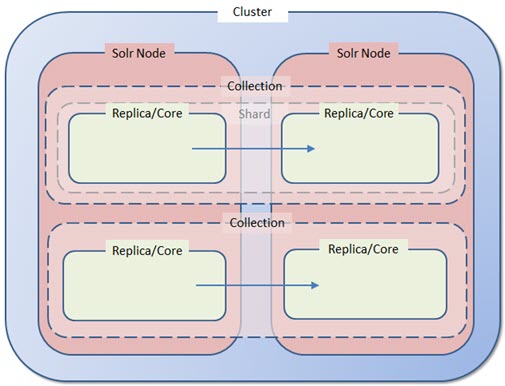
Collection
Eine Collection ist eine logische Gruppe von Dokumenten, die innerhalb eines verteilten Solr-Clusters als zusammengehörige Einheit betrachtet wird. Eine Collection kann über mehrere Shards auf verschiedene Nodes verteilt sein und nutzt gemeinsame Konfigurationsdateien zur Verwaltung von Indexierungs- und Suchparametern.
Shard
Ein Shard ist eine Partition eines Indexes innerhalb einer Collection. Durch die Aufteilung in Shards wird die Verarbeitung von Daten über mehrere Nodes hinweg ermöglicht. Jeder Shard enthält einen Teil der gesamten Collection und arbeitet unabhängig an der Speicherung und Verarbeitung der darin enthaltenen Dokumente.
Replica
Eine Replica ist eine exakte Kopie eines Shards und wird zur Verbesserung der Verfügbarkeit und Lastverteilung innerhalb eines Clusters verwendet. Replicas können Leseanfragen bearbeiten und bei einem Ausfall eines Shards dessen Funktion übernehmen.
Document
Ein Document ist die grundlegende Informationseinheit innerhalb von Solr. Jedes Dokument besteht aus mehreren Feldern, die verschiedene Attribute oder Metadaten enthalten. Dokumente werden indexiert, um später anhand von Suchanfragen abgerufen werden zu können.
Field
Ein Field ist ein Bestandteil eines Dokuments und speichert spezifische Informationen. Jedes Feld hat einen vordefinierten Datentyp, der festlegt, wie die enthaltenen Werte behandelt und durchsucht werden können. Felder können sowohl einfache Werte als auch mehrwertige Einträge enthalten.
Schema
Das Schema definiert die Struktur und Eigenschaften der in Solr gespeicherten Dokumente. Es bestimmt, welche Felder in einem Dokument existieren, welche Datentypen sie haben und welche Analysemethoden bei der Indexierung angewendet werden. Das Schema kann statisch definiert oder durch dynamische Felddefinitionen flexibel erweitert werden.
Query
Eine Query ist eine Abfrage, die an Solr gesendet wird, um nach bestimmten Informationen im Index zu suchen. Solr bietet verschiedene Abfragesprachen, darunter die Standard-Query-Syntax von Lucene. Suchanfragen können durch Filter, Sortierungen und andere Parameter angepasst werden.
ZooKeeper
ZooKeeper ist ein verteiltes Koordinationssystem, das für die Verwaltung von verteilten Anwendungen verwendet wird. In Solr übernimmt ZooKeeper die Aufgaben der Konfigurationsverwaltung, Cluster-Koordination und Statusüberwachung der Nodes. Es sorgt für die Synchronisation zwischen den einzelnen Solr-Nodes und gewährleistet die Konsistenz innerhalb des Clusters.
Solr Cluster Types
Apache Solr bietet zwei Hauptbetriebsmodi, die je nach spezifischen Anforderungen, Skalierbarkeitsbedürfnissen und Verwaltungsaufwand gewählt werden können. Diese beiden Betriebsmodi sind SolrCloud-Modus und User-Managed-Modus. Während SolrCloud für hochverfügbare und automatisierte Suchlösungen in verteilten Umgebungen entwickelt wurde, bietet der User-Managed-Modus mehr Kontrolle, erfordert jedoch eine manuelle Verwaltung aller Aspekte des Systems.
SolrCloud-Modus
SolrCloud ist der empfohlene Betriebsmodus für große, verteilte Suchanwendungen, die eine hohe Verfügbarkeit, Fehlertoleranz und automatische Skalierbarkeit erfordern. In diesem Modus werden alle Solr-Knoten durch Apache ZooKeeper koordiniert, das für das Management der Konfiguration, die Verteilung von Anfragen und die Überwachung des Systemzustands verantwortlich ist.
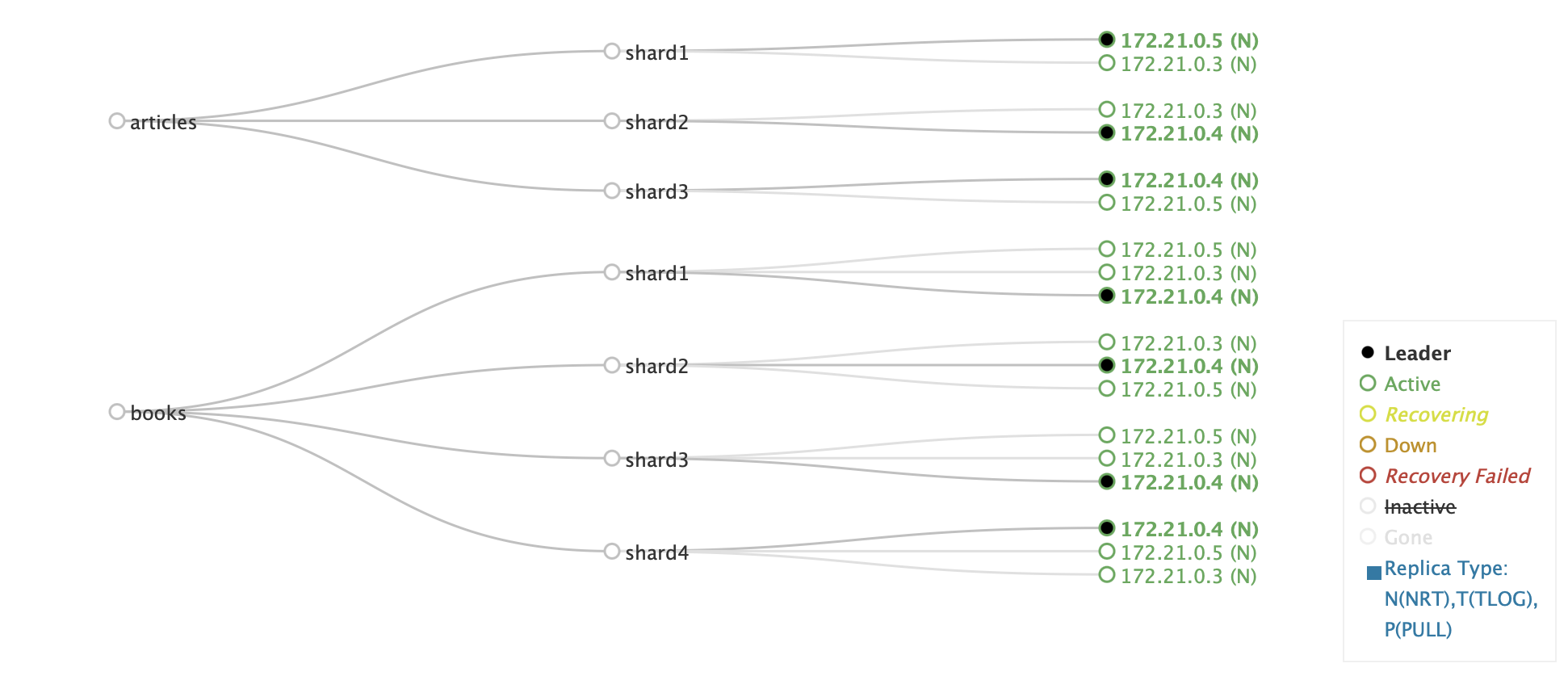
Ein zentrales Konzept in SolrCloud ist die Collection, die als logische Gruppierung von Dokumenten dient. Eine Collection kann in mehrere Shards unterteilt werden, wobei jeder Shard einen Teil des Indexes enthält. Jeder Shard wiederum kann mehrere Replikate haben, die die Datenverfügbarkeit sicherstellen und Suchanfragen effizient verteilen. SolrCloud übernimmt die automatische Verwaltung dieser Struktur und sorgt dafür, dass Dokumente gleichmäßig über die verfügbaren Shards verteilt werden.
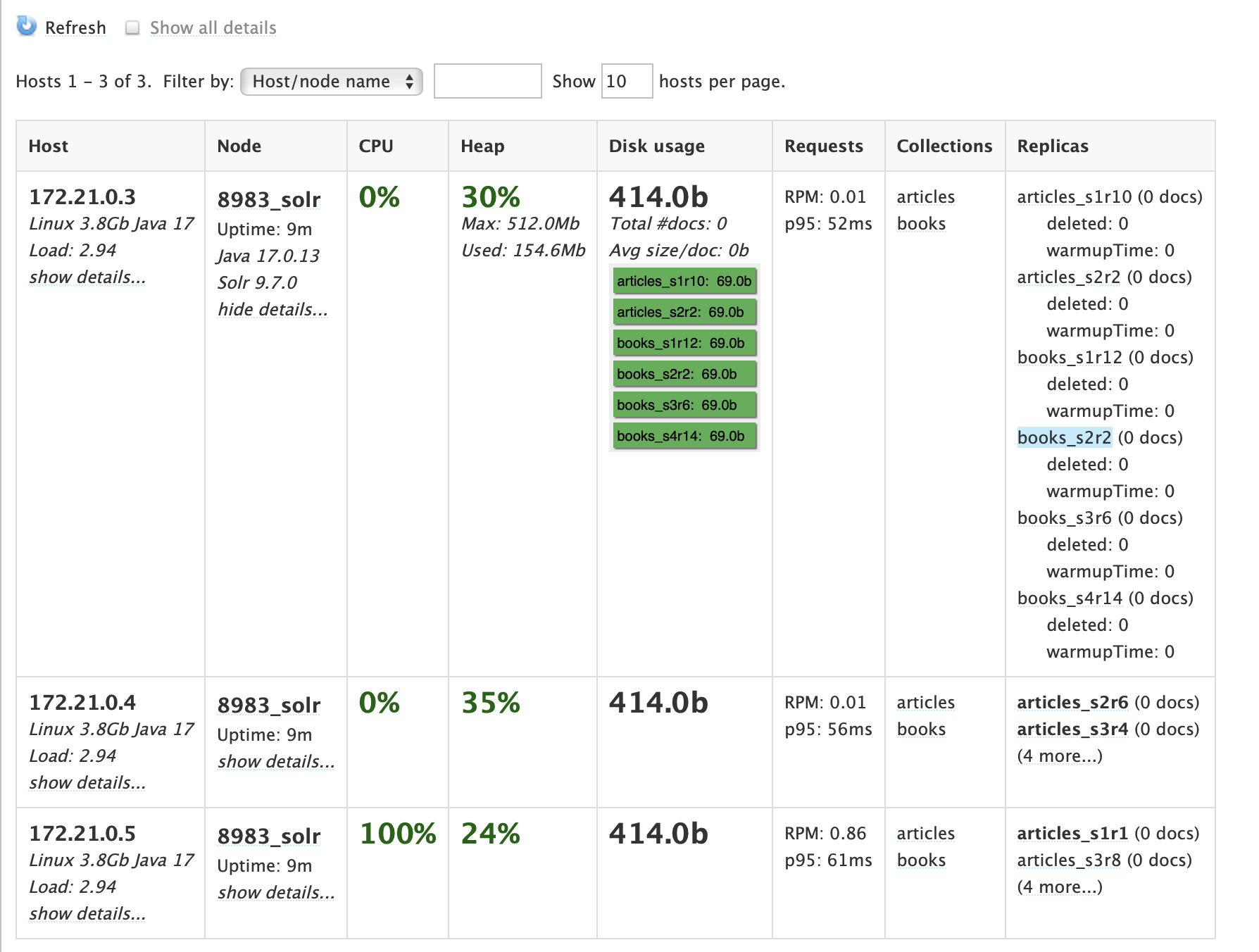
Eine der wesentlichen Eigenschaften von SolrCloud ist das automatische Sharding und Failover-Management. Wenn ein neuer Knoten dem Cluster hinzugefügt wird, kann Solr automatisch neue Shards erstellen oder bestehende Shards auf den neuen Knoten verschieben. Falls ein Knoten ausfällt, übernimmt eine vorhandene Replica dessen Aufgaben, wodurch der Betrieb nahtlos weiterläuft. Darüber hinaus gibt es eine Leader-Wahl-Mechanismus, bei dem jeder Shard einen Leader hat, der für die Indexierung verantwortlich ist. Falls ein Leader ausfällt, wird automatisch eine neue Leader-Wahl durchgeführt, um den reibungslosen Betrieb aufrechtzuerhalten.
Da SolrCloud auf zentrale Konfigurationsverwaltung setzt, werden alle Konfigurationsdateien in ZooKeeper gespeichert. Änderungen an Indexierungsregeln, Schema-Definitionen oder Replikationsstrategien werden zentral verwaltet und auf alle Knoten im Cluster angewendet. Diese Architektur ermöglicht eine flexible Skalierung und eine effiziente Nutzung der Ressourcen.
SolrCloud eignet sich besonders für große Unternehmen und Anwendungen, die eine nahtlose Skalierbarkeit, hohe Verfügbarkeit und minimalen Verwaltungsaufwand erfordern. Es ist eine bevorzugte Lösung für Suchdienste, die große Datenmengen effizient verwalten und kontinuierlich aktualisieren müssen.
User-Managed Mode
Der User-Managed-Modus, auch als Standalone-Modus bezeichnet, ist eine traditionelle Betriebsart von Solr, die sich für kleinere oder manuell verwaltete Suchanwendungen eignet. Im Gegensatz zu SolrCloud erfolgt die Verwaltung von Knoten, Indexen und Replikationen manuell, ohne die zentrale Steuerung durch Apache ZooKeeper.
In diesem Modus besteht ein Cluster aus mehreren Nodes, die unabhängig voneinander betrieben werden. Jeder Node kann mehrere Cores enthalten, die jeweils eigenständige Indizes verwalten. Die Verteilung von Dokumenten und die Aufteilung von Shards sind nicht automatisiert – der Administrator muss entscheiden, wie die Daten organisiert und aufgeteilt werden. Da es keine automatische Verteilung gibt, müssen Sharding-Strategien und Lastverteilungen im Voraus geplant werden.
Ein wesentlicher Bestandteil des User-Managed-Modus ist das Leader-Follower-Replikationsmodell. Dabei übernimmt ein Leader-Core die Indexierung von Dokumenten und verteilt die Änderungen an Follower-Cores, die Kopien des Indexes speichern. Im Gegensatz zu SolrCloud erfolgt diese Replikation nicht automatisch – sie muss explizit konfiguriert werden, um sicherzustellen, dass alle Knoten synchron bleiben.
Die Konfigurationsverwaltung im User-Managed-Modus erfolgt lokal auf jedem Node. Konfigurationsdateien und Schema-Definitionen werden auf dem Dateisystem gespeichert und müssen manuell zwischen den Knoten synchronisiert werden. Änderungen an der Indexstruktur oder den Replikationseinstellungen müssen für jede Solr-Instanz separat vorgenommen werden, was den Verwaltungsaufwand erheblich erhöht.
Während der User-Managed-Modus mehr Kontrolle über die einzelnen Komponenten bietet, fehlen ihm viele der automatisierten Funktionen von SolrCloud. Da es kein automatisches Failover-Management gibt, muss ein ausgefallener Knoten manuell neu gestartet oder ersetzt werden. Auch die Skalierung erfordert zusätzlichen Verwaltungsaufwand, da neue Knoten nicht automatisch erkannt oder in das System integriert werden.
Dieser Modus eignet sich für kleinere Anwendungen, die keine verteilte Architektur benötigen oder in denen eine detaillierte Kontrolle über die Indexierungs- und Suchprozesse erforderlich ist. Er ist insbesondere dann nützlich, wenn eine spezifische Sharding-Strategie implementiert oder besondere Anforderungen an die Datenverarbeitung gestellt werden.
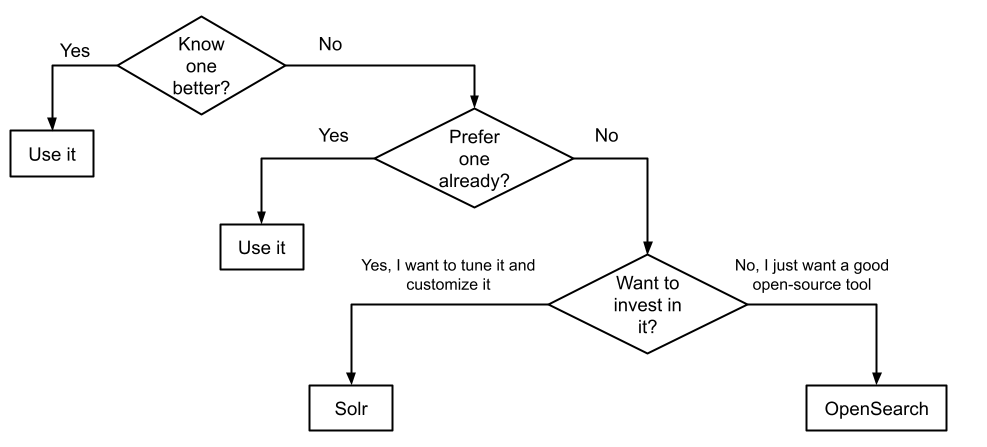
Vergleich mit anderen Suchplattformen
Neben Solr gibt es weitere leistungsfähige Suchmaschinen wie Elasticsearch und OpenSearch, die ebenfalls auf Lucene basieren. Während alle drei Systeme leistungsstarke Such- und Indexierungsfunktionen bieten, gibt es einige wesentliche Unterschiede.
Elasticsearch
Elasticsearch wurde 2010 von Elastic N.V. entwickelt und ist eine verteilte, RESTful-Such- und Analyse-Engine, die für hohe Skalierbarkeit, Echtzeit-Suche und Datenanalyse optimiert ist. Während es ursprünglich als Open-Source-Software entwickelt wurde, unterliegt es seit Version 7.11 der Server Side Public License (SSPL), die seine Nutzung in verwalteten Cloud-Diensten einschränkt.
Architektur und Cluster-Management
Elasticsearch setzt auf eine vollständig verteilte Architektur, die eine automatische Verwaltung von Knoten, Shards und Replikaten bietet. Diese Struktur erleichtert horizontale Skalierung, indem Daten gleichmäßig über mehrere Nodes verteilt werden. Im Gegensatz dazu benötigt Solr Apache ZooKeeper für die Cluster-Koordination und manuelle Shard-Verwaltung.
Ein bedeutender Vorteil von Elasticsearch ist die automatische Lastverteilung und Rebalancing-Funktion, die Cluster automatisch an veränderte Lastbedingungen anpasst. In Solr müssen diese Anpassungen manuell oder über ZooKeeper gesteuert werden, was zu einem höheren Verwaltungsaufwand führt.
Indexierung und Echtzeit-Verarbeitung
Elasticsearch bietet Echtzeit-Indexierung, die es ermöglicht, neue oder aktualisierte Dokumente sofort durchsuchbar zu machen. Es nutzt ein speicherbasiertes Schreibmodell, das Änderungen ohne explizite Commits sofort sichtbar macht. Solr hingegen setzt auf Commit-basierte Aktualisierungen, die standardmäßig eine Verzögerung zwischen Indexierung und Suchbarkeit mit sich bringen können.
Such- und Abfragefunktionen
Elasticsearch bietet eine benutzerfreundliche, flexible API mit JSON-basierten Suchanfragen, die für Entwickler leicht zu implementieren sind. Es unterstützt nested data analytics, was komplexe Abfragen innerhalb von verschachtelten Dokumentstrukturen ermöglicht. Im Gegensatz dazu verwendet Solr die Lucene Query-Syntax und XML-basierten Anfragen, die für einige Anwendungen mehr Kontrolle bieten.
Ein weiterer wesentlicher Unterschied ist die Optimierung für strukturierte und unstrukturierte Daten. Während Solr auf Volltextsuche spezialisiert ist, bietet Elasticsearch umfassende Analysefunktionen für Zeitreihen- und numerische Daten. Dies macht es besonders geeignet für Log-Analysen, Business Intelligence und Monitoring.
Einschränkungen und Lizenzierung
Obwohl Elasticsearch eine leistungsfähige Suchplattform ist, gibt es Einschränkungen. Die SSPL-Lizenz bedeutet, dass es nicht vollständig Open Source ist. Unternehmen, die Elasticsearch als verwalteten Cloud-Dienst nutzen möchten, müssen sich an die Lizenzbedingungen halten, die kommerzielle Nutzung einschränken. Zudem erlaubt Elasticsearch keine Entfernung oder Anpassung der Lizenzinformationen in seiner Distribution.

OpenSearch
OpenSearch wurde 2021 von Amazon Web Services (AWS) als Open-Source-Fork von Elasticsearch entwickelt, nachdem Elastic die Lizenz von Elasticsearch auf die Server-Side Public License (SSPL) umgestellt hatte. OpenSearch bleibt hingegen unter der Apache 2.0-Lizenz und stellt eine vollständig freie Alternative dar.
Architektur und Cluster-Management
OpenSearch wurde für eine einfache Verwaltung und horizontale Skalierbarkeit entwickelt. Es bietet eine integrierte automatische Clusterverwaltung, die Shard-Verteilung und Replikation ohne manuelle Konfiguration übernimmt. Dadurch lassen sich große Datenmengen effizient verarbeiten, ohne dass ein externes Koordinierungssystem erforderlich ist. Die eingebaute Lastverteilung stellt sicher, dass Knoten im Cluster optimal genutzt werden und dass bei einem Ausfall eines Knotens automatisch ein Failover erfolgt.
Die Architektur von OpenSearch macht es besonders geeignet für dynamische Workloads, da es automatisch erkennt, wenn neue Knoten hinzugefügt werden, und die Verteilung der Daten entsprechend anpasst. Diese automatische Skalierung reduziert den Verwaltungsaufwand erheblich und ermöglicht eine problemlose Erweiterung bei steigenden Anforderungen.
Indexierung und Echtzeit-Verarbeitung
OpenSearch nutzt ein Echtzeit-Indizierungssystem, das es ermöglicht, neue oder aktualisierte Daten sofort für Suchanfragen verfügbar zu machen. Im Gegensatz zu traditionell commit-basierten Systemen sind Änderungen unmittelbar sichtbar, was besonders für hochfrequente Datenaktualisierungen von Vorteil ist. Dies macht OpenSearch ideal für Anwendungsfälle wie Log-Analysen, Monitoring und Business Intelligence, bei denen Daten kontinuierlich verarbeitet und sofort abrufbar sein müssen.
API-Design und Benutzerfreundlichkeit
OpenSearch verwendet eine moderne RESTful JSON-API, die eine einfache Integration in bestehende Systeme ermöglicht. Die API ist klar strukturiert, gut dokumentiert und erleichtert Entwicklern die Arbeit mit verschachtelten Abfragen, Filterungen und Aggregationen. Durch die intuitive Syntax ist OpenSearch besonders zugänglich für Benutzer, die ein leicht verständliches Abfragesystem benötigen.
Neben der API bietet OpenSearch eine visuelle Benutzeroberfläche, die die Verwaltung und Analyse von Daten erleichtert. OpenSearch Dashboards ermöglichen eine interaktive Visualisierung von Suchergebnissen, Metriken und Logs, wodurch es sich ideal für Echtzeit-Überwachungen und interaktive Datenanalysen eignet.
Lizenzierung und Open-Source-Entwicklung
OpenSearch wird von Amazon Web Services (AWS) entwickelt und bleibt unter der Apache 2.0-Lizenz vollständig Open Source. Diese Lizenz erlaubt eine uneingeschränkte kommerzielle Nutzung, ohne dass zusätzliche Restriktionen bestehen. Die Entwicklung erfolgt durch eine offene Community, wodurch das Projekt kontinuierlich verbessert und weiterentwickelt wird.
OpenSearch ist ideal für Unternehmen und Entwickler, die eine skalierbare, einfach zu verwaltende Open-Source-Suchlösung mit Echtzeit-Indizierung, automatischer Clusterverwaltung und modernen API-Funktionen suchen. Es eignet sich besonders für dynamische Datenverarbeitung, bei der Suchanfragen schnell auf neue Informationen reagieren müssen. Zudem ist OpenSearch eine optimale Lösung für Big-Data-Analysen, da es leistungsstarke Aggregations- und Visualisierungswerkzeuge integriert.
Fazit
Apache Solr ist eine leistungsstarke Open-Source-Suchmaschine, die sich durch Volltextsuche, flexible Anpassungsmöglichkeiten und Skalierbarkeit auszeichnet. Dank seiner starken Unterstützung für Facettierung, Relevanzbewertung und Geodatenabfragen bietet es eine umfassende Kontrolle über Indexierungs- und Suchprozesse. Die Architektur von SolrCloud ermöglicht eine verteilte Verarbeitung großer Datenmengen, wobei Apache ZooKeeper für die Cluster-Verwaltung sorgt und Sharding sowie Replikation effizient steuert.
Im Vergleich zu anderen Suchsystemen wie Elasticsearch und OpenSearch bietet Solr eine höhere Anpassbarkeit und tiefgehende Steuerungsmöglichkeiten über das Ranking und die Indexierung. Während Elasticsearch und OpenSearch stärker auf Echtzeit-Datenverarbeitung, automatische Clusterverwaltung und integrierte Analysefunktionen ausgerichtet sind, setzt Solr auf eine feinjustierbare Sucharchitektur, die eine präzise Steuerung von Relevanz, Facettierung und Abfrageoptimierung erlaubt.
Solr eignet sich besonders für Anwendungen, die eine hohe Kontrolle über Suchprozesse, anpassbare Relevanzbewertung und detaillierte Indexkonfigurationen erfordern. In Umgebungen, in denen eine maximale Anpassung der Suchalgorithmen und ein strukturiertes Index-Management erforderlich sind, bleibt Solr eine führende Wahl. Die bewährte Architektur und die große Community hinter Solr garantieren eine kontinuierliche Weiterentwicklung und langfristige Stabilität, was es zu einer verlässlichen Suchlösung für datenintensive Anwendungen macht.
Quellen
- https://solr.apache.org/guide/solr/latest/getting-started/introduction.html
- https://solr.apache.org/guide/solr/latest/deployment-guide/cluster-types.html
- https://solr.apache.org/guide/solr/latest/deployment-guide/solrcloud-shards-indexing.html
- https://solr.apache.org/guide/solr/latest/deployment-guide/user-managed-index-replication.html
- https://en.wikipedia.org/wiki/Apache_Solr
- https://sematext.com/guides/solr/
- https://medium.com/@mansha99/apache-solr-fundamentals-43e360962cc8
- https://www.searchstax.com/docs/hc/solr-collection-core-shard-replica/
- https://dattell.com/data-architecture-blog/solr-vs-elasticsearch/
- https://sematext.com/blog/opensearch-vs-solr/