Apache Jena Fuseki
Übersicht
Apache Jena Fuseki ist ein HTTP-basierter SPARQL-Server, der als zentrale Schnittstelle für das Speichern, Abfragen und Verarbeiten von RDF-Daten dient. Er gehört zum Apache-Jena-Framework und stellt standardisierte Endpunkte bereit, über die Wissensgraphen und semantische Datenmodelle effizient verwaltet werden können.
Durch seine Unterstützung offener Webstandards wie RDF und SPARQL ermöglicht Fuseki eine flexible, systemunabhängige Integration in moderne Anwendungen – von Forschung und Wissensmanagement bis hin zu Linked-Data-Projekten und intelligenten Informationssystemen.
Was ist Apache Jena Fuseki?
Apache Jena Fuseki ist ein zentraler Bestandteil des Apache-Jena-Ökosystems und dient als HTTP-basierter SPARQL-Server, der speziell für die Arbeit mit RDF-Daten entwickelt wurde. Er stellt standardisierte Webschnittstellen bereit, über die sich Daten speichern, abfragen und aktualisieren lassen. Damit bildet Fuseki das Rückgrat moderner Wissensgraph-Architekturen, bei denen Informationen nicht nur gesammelt, sondern in ihren Beziehungen und Bedeutungen verstanden werden sollen.
Eingesetzt wird Fuseki überall dort, wo semantische Datenmodelle eine zentrale Rolle spielen — beispielsweise in unternehmensweiten Wissensgraphen, Forschungsdatenplattformen, Ontologie-basierten Anwendungen oder staatlichen Open-Data-Portalen. Die Stärke des Systems liegt darin, Daten nicht als isolierte Werte zu behandeln, sondern als verknüpfte Einheiten, die sich über standardisierte Abfragesprachen analysieren lassen.
Fuseki unterstützt eine große Bandbreite etablierter Webstandards wie RDF 1.1, SPARQL 1.1 (für sowohl Abfragen als auch Updates), das Graph Store Protocol und verschiedene Austauschformate wie JSON-LD, Turtle, N-Triples oder RDF/XML. Diese konsequente Orientierung an W3C-Standards stellt sicher, dass Fuseki problemlos in unterschiedliche Plattformen und Architekturen integriert werden kann — unabhängig von Programmiersprache oder Technologie.
Unterstützte Standards
- RDF 1.1
- SPARQL 1.1 (Query + Update)
- Graph Store Protocol
- JSON-LD, Turtle, N-Triples, RDF/XML
Anwendungsbereiche
Apache Jena Fuseki kommt immer dann zum Einsatz, wenn Daten nicht nur gespeichert, sondern in ihren Bedeutungen und Beziehungen verstanden werden sollen. Im Zentrum stehen Wissensgraphen, also Datenmodelle, bei denen Zusammenhänge eine ebenso große Rolle spielen wie die eigentlichen Inhalte.
Ein typischer Anwendungsbereich ist das Wissensmanagement in Unternehmen. Durch die strukturierte Verknüpfung von Informationen entstehen semantische Modelle, die komplexe Abhängigkeiten sichtbar machen und den Zugriff auf Unternehmenswissen erleichtern.
Auch in der Forschung und in Bibliotheken hat sich Fuseki etabliert: Forschungsdaten, Publikationen oder bibliografische Einträge lassen sich als miteinander verknüpfte Datensätze darstellen. Dadurch werden Analysen, Abfragen und Recherchen deutlich effizienter.
Im öffentlichen Sektor dient Fuseki häufig als Plattform für Linked Open Data, da Behörden damit Daten standardisiert und maschinenlesbar bereitstellen können. Dies steigert die Transparenz und ermöglicht die Weiterverarbeitung der Informationen durch externe Anwendungen.
Weitere wichtige Einsatzfelder liegen in Empfehlungssystemen, die Beziehungen zwischen Nutzern, Objekten und Inhalten auswerten, sowie im Internet of Things (IoT), wo heterogene Sensordaten semantisch integriert werden müssen.
Schließlich spielt Fuseki eine zentrale Rolle im Healthcare-Bereich, etwa bei medizinischen Wissensgraphen, Ontologien oder der semantischen Verknüpfung von Patientendaten — immer dort, wo aus Daten kontextbezogenes Wissen entsteht.
Warum Fuseki?
Die besondere Stärke von Apache Jena Fuseki liegt in seiner konsequenten Ausrichtung auf offene Webstandards. Durch die vollständige Unterstützung von RDF, SPARQL und HTTP lässt sich Fuseki nahtlos in unterschiedlichste technische Umgebungen integrieren — unabhängig davon, ob Anwendungen in Java, Python, JavaScript oder einer anderen Sprache entwickelt wurden. Diese Interoperabilität macht Fuseki besonders attraktiv für heterogene Systemlandschaften, wie sie heute in vielen Organisationen üblich sind.
Ein weiterer Grund für den Einsatz von Fuseki ist seine Eignung für moderne, serviceorientierte Architekturen. Wissensgraphen können als eigenständiger Dienst betrieben werden, der klar definierte Endpunkte bereitstellt. Dadurch bleiben Systeme modular, gut wartbar und flexibel erweiterbar. Fuseki lässt sich problemlos skalieren und sowohl in kleinen Forschungsprojekten als auch in produktiven Unternehmensumgebungen einsetzen.
Besonders hervorzuheben ist zudem die Möglichkeit, Reasoning einzubinden. In Kombination mit dem Jena-Reasoner können aus vorhandenen RDF-Daten neue Schlussfolgerungen abgeleitet werden, die nicht explizit gespeichert sind, sich aber logisch ergeben. Dieses Feature verleiht Anwendungen eine zusätzliche Ebene „semantischer Intelligenz“ und ermöglicht präzisere Analysen, automatisierte Klassifikationen und ein tieferes Verständnis komplexer Datenmodelle.
Insgesamt bietet Fuseki eine Kombination aus Offenheit, Flexibilität und semantischer Ausdrucksstärke, die es zu einem zentralen Werkzeug für datengetriebene Systeme macht, die über herkömmliche Datenbanken hinausgehen.
Kernkomponenten von Fuseki
Die Architektur von Apache Jena Fuseki setzt sich aus mehreren zentralen Komponenten zusammen, die gemeinsam dafür sorgen, dass RDF-Daten effizient verwaltet und über standardisierte Schnittstellen bereitgestellt werden können. Das Herzstück bildet der SPARQL-Endpoint, über den Abfragen und Updates entgegengenommen werden. Fuseki stellt hierfür verschiedene Endpunkte bereit: einen reinen Query-Endpunkt für SELECT-, ASK- und CONSTRUCT-Abfragen, einen Update-Endpunkt für INSERT- und DELETE-Operationen sowie kombinierte Schnittstellen, die Abfrage- und Schreiboperationen an einem einzigen Zugangspunkt bündeln. Zusätzlich können über dedizierte Endpunkte auch RDF-Daten hochgeladen oder extrahiert werden.
Eine weitere tragende Säule ist das Dataset Management. Fuseki unterstützt unterschiedliche Speicherformen, die je nach Anwendungsfall ausgewählt werden können. Für kleinere Experimente oder Tests eignet sich der In-Memory-Speicher, der schnelle Ladezeiten und flexible Manipulationen ermöglicht. Für Produktionsumgebungen bietet das TDB- bzw. TDB2-Backend eine persistente Triple-Store-Option, die große Datenmengen zuverlässig verwaltet. Darüber hinaus können externe RDF-Dateien eingebunden oder hybride Speicherlösungen verwendet werden, wodurch Fuseki vielfältige Einsatzszenarien abdeckt.
Ein entscheidender Bestandteil in sicherheitskritischen Umgebungen ist die Integration von Apache Shiro für Authentifizierung und Autorisierung. Dadurch können Benutzer, Rollen und Berechtigungen granular definiert werden. Ob einfache Basic-Auth oder komplexere Token-basierte Ansätze: Fuseki lässt sich flexibel absichern und mit HTTPS oder Reverse Proxies kombinieren, um einen Schutz auf mehreren Ebenen zu gewährleisten.
Ergänzt wird das System durch eine Web-basierte Benutzeroberfläche, die Administratoren und Entwicklern ermöglicht, Datasets zu verwalten, RDF-Daten hochzuladen und SPARQL-Abfragen interaktiv auszuführen. Diese Oberfläche erleichtert nicht nur den Einstieg, sondern ist auch im täglichen Betrieb ein wertvolles Werkzeug.
Abgerundet wird Fuseki durch die optionale Reasoning Engine des Jena-Frameworks. Je nach Modell können RDFS-, OWL- oder regelbasierte Reasoner eingebunden werden, um logische Inferenzen über den Daten auszuführen. Dadurch lassen sich zusätzliche Erkenntnisse ableiten, die nicht explizit gespeichert sind, sich jedoch aus dem semantischen Modell ergeben.
Installation & Deployment
Für den Einsatz von Apache Jena Fuseki stehen drei unterschiedliche Betriebsarten zur Verfügung, die je nach technischen Anforderungen und Projektumgebung gewählt werden können.
1. Standalone-Modus
Im Standalone-Modus wird Fuseki direkt als eigenständige Anwendung ausgeführt. Nach dem Download von der offiziellen Apache-Seite kann der Server ohne zusätzliche Konfiguration über die Kommandozeile gestartet werden. Diese Variante eignet sich besonders für lokale Entwicklungsumgebungen oder kleinere Projekte, die keine komplexen Deployments benötigen.
2. Docker-Deployment (empfohlen)
Für flexible, portable und skalierbare Umgebungen bietet sich die Nutzung eines Docker-Containers an. Durch die Containerisierung lässt sich Fuseki plattformunabhängig und reproduzierbar bereitstellen. Der Server wird einfach über einen docker run-Befehl gestartet, und die Weboberfläche ist anschließend unter http://localhost:3030 erreichbar. Diese Methode ist optimal für produktive Systeme oder Teams, die konsistente Entwicklungsumgebungen benötigen.
3. Embedded Server
Für Microservices oder Java-basierte Anwendungen kann Fuseki direkt in den Anwendungscode eingebettet werden. Die API ermöglicht das Erstellen und Starten eines Servers innerhalb der eigenen Anwendung, wodurch sich RDF-Daten ohne externen Server verarbeiten lassen. Dadurch wird eine enge Integration mit bestehenden Software-Architekturen erreicht.
Architekturmodell von Apache Jena
Das Architekturmodell von Apache Jena bildet die strukturelle Grundlage für die Verarbeitung, Speicherung und Abfrage semantischer Daten im Rahmen des Semantic Web. Es umfasst mehrere klar abgegrenzte, aber eng miteinander verzahnte Module, die unterschiedliche Funktionalitäten bereitstellen und so eine flexible Nutzung in verschiedensten Anwendungsszenarien ermöglichen.
Im Zentrum der Architektur stehen die RDF-, Ontology- und SPARQL-APIs, welche Anwendungen den Zugriff auf RDF-Daten, Ontologiemodelle sowie die Ausführung komplexer SPARQL-Abfragen ermöglichen. Die Parser- und Writer-Komponenten unterstützen zahlreiche gängige Serialisierungsformate wie Turtle, JSON-LD und RDF/XML und stellen sicher, dass Daten problemlos zwischen verschiedenen Systemen ausgetauscht werden können.
Die Inference API ermöglicht es, logische Schlussfolgerungen aus vorhandenen Daten abzuleiten. Dabei können sowohl eingebaute Reasoner als auch externe Engines verwendet werden, um regelbasierte oder semantische Inferenzmechanismen wie RDFS- und OWL-Reasoning anzuwenden.
Für die Datenspeicherung bietet die Store API verschiedene Optionen: vom schnellen In-Memory-Speicher über den persistenten TDB-Datenspeicher bis hin zu benutzerdefinierten Speicherlösungen. Diese Flexibilität erlaubt es, Jena in sowohl leichten Anwendungen als auch in skalierbaren produktiven Systemen einzusetzen.
Durch diese modulare und erweiterbare Architektur kann Apache Jena als leistungsfähiges Fundament für semantische Webanwendungen, Wissensgraphen und Linked-Data-Plattformen dienen. Die folgende Abbildung veranschaulicht den strukturellen Aufbau der Jena-Komponenten: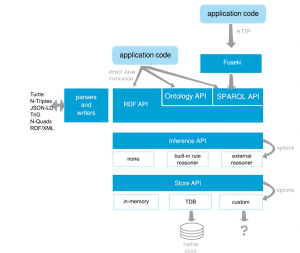
Authentifizierung mit Apache Shiro
Für die Absicherung von SPARQL-Endpunkten verwendet Apache Fuseki das Framework Apache Shiro, das eine flexible und leicht konfigurierbare Zugriffskontrolle ermöglicht. Die Konfiguration erfolgt über die Datei shiro.ini, in der sowohl Benutzer- und Rollenmodelle als auch spezifische Zugriffsregeln für einzelne Endpunkte definiert werden können.
Im ersten Schritt werden Benutzer und ihre zugehörigen Rollen festgelegt. Die Konfiguration erlaubt es, verschiedene Berechtigungsstufen zu definieren, beispielsweise einen Administrator mit vollständigen Rechten sowie einen Leser mit beschränktem Zugriff auf bestimmte SPARQL-Operationen. Jede Rolle kann mit unterschiedlichen Berechtigungen verknüpft werden, wodurch eine klare Trennung zwischen Lese- und Schreibzugriffen möglich ist. Dies ist insbesondere in produktiven Umgebungen von Bedeutung, in denen Schreiboperationen nur ausgewählten Benutzern gestattet sein sollen.
Anschließend werden in der shiro.ini spezifische Regeln für URL-basierte Zugriffe definiert. Hierbei kann für jeden Endpunkt einzeln festgelegt werden, ob dieser öffentlich zugänglich ist oder ob eine Authentifizierung bzw. eine bestimmte Rolle erforderlich ist. Im gezeigten Beispiel bleiben reine Leseendpunkte, wie der SPARQL-Query-Service, öffentlich zugänglich, während Schreiboperationen – wie SPARQL-UPDATE – ausschließlich Benutzern mit Administratorrechten vorbehalten sind. Dadurch wird gewährleistet, dass der Datenbestand geschützt bleibt und unautorisierte Änderungen verhindert werden.
Die Integration von Apache Shiro bietet somit eine robuste und zugleich flexible Möglichkeit, Fuseki-Server in sicherheitskritischen Umgebungen zu betreiben. Durch die Kombination aus rollenbasierter Zugriffskontrolle und feingranularer Endpunkt-Konfiguration können individuelle Sicherheitsanforderungen präzise abgebildet werden, ohne den Verwaltungsaufwand zu erhöhen.
Beispiel: SPARQL Query und Update
Zur Veranschaulichung der zuvor beschriebenen Funktionen von Apache Fuseki wird im Folgenden ein konkretes Beispiel vorgestellt, das den gesamten Prozess der Datenverarbeitung anhand eines RDF-Datensatzes demonstriert. Das Beispiel umfasst das Laden von RDF-Daten, das Ausführen einer SPARQL-SELECT-Abfrage sowie das Einfügen neuer Daten mittels SPARQL-INSERT.
1. RDF-Daten laden
Zunächst wird ein RDF-Datensatz in Turtle-Syntax erstellt, der eine Beispielressource Student1 beschreibt. Die Ressource verfügt über die Eigenschaften name und studies, die im Beispiel mit „John Doe“ und „Informatik“ belegt sind. Diese RDF-Datei kann anschließend über die Kommandozeile in einen Fuseki-Datensatz geladen werden.
Der Import erfolgt über den Befehl, mit dem eine Turtle-Datei in das gewünschte Dataset übertragen wird. Dies ermöglicht ein effizientes Initialisieren der Datenbasis und dient typischerweise als erster Schritt in semantischen Webanwendungen, bevor Abfragen oder Updates durchgeführt werden.
2. SPARQL-Query ausführen
Nach dem Laden des Datensatzes kann die Information mittels einer SPARQL-SELECT-Abfrage ausgelesen werden. In diesem Beispiel wird eine SPARQL-Query formuliert, die den Namen und das Studienfach des Studenten extrahiert. Diese Abfrage kann direkt über die Fuseki-Weboberfläche oder alternativ über einen HTTP-Request ausgeführt werden.
Die Nutzung eines HTTP-Endpunkts zeigt dabei, wie SPARQL-Abfragen problemlos in externe Anwendungen integriert werden können. Dies ist besonders relevant für Systeme, die semantische Daten automatisiert verarbeiten oder regelmäßig abfragen müssen.
3. SPARQL Update (INSERT)
Abschließend wird demonstriert, wie sich der bestehende Datensatz durch SPARQL-Update erweitern lässt. Hier wird eine neue Ressource Student2 eingefügt, der die Eigenschaften „Alice“ sowie „Mathematik“ zugewiesen werden. Der INSERT-Befehl ergänzt den RDF-Graphen um neue Tripel, ohne bestehende Informationen zu überschreiben.
Die Update-Operation kann ebenfalls über die Weboberfläche oder als HTTP-POST-Request durchgeführt werden. Insbesondere die HTTP-Variante ermöglicht eine automatisierte Integration in Client-Anwendungen, die kontinuierlich Daten in den Fuseki-Server einspeisen.
Dieses Beispiel zeigt den typischen Workflow bei der Arbeit mit Apache Fuseki: Daten werden geladen, abgefragt und anschließend erweitert. Die Kombination aus RDF, SPARQL und der leicht bedienbaren Fuseki-Oberfläche bietet dabei ein leistungsfähiges Werkzeug zur Verwaltung semantischer Datenbestände und bildet eine zentrale Grundlage für den Aufbau und Betrieb von Wissensgraphen.
Integration der FahrMemo-Webanwendung mit Apache Jena Fuseki
Die im Folgenden vorgestellte Webanwendung FahrMemo wurde im Jahr 2024 von der Autorin,Sarah Kiki, im Rahmen ihre Bachelorarbeit entwickelt. Ziel der Anwendung ist es, Fahrdaten strukturiert zu erfassen und über Apache Jena Fuseki als Wissensgraph zu speichern und auszuwerten.
Die Webanwendung FahrMemo nutzt Apache Jena Fuseki als Triple Store, um die in der Fahrschule entstehenden Daten – etwa Schülerstammdaten, Fahrstunden und Vorprüfungsbewertungen – als Wissensgraph abzulegen und wieder abzurufen. Grundlage dafür ist eine Ontologie mit den Klassen Student und DrivingLesson sowie deren Unterklassen, über die alle Formulareingaben der App in RDF-Tripel überführt werden.
Datenübertragung und Speicherung
Sobald ein Fahrlehrer im Frontend ein Formular – z. B. das Schülerdatenformular oder eine Fahrstundendokumentation – speichert, werden die Eingaben im Backend zunächst validiert und anschließend anhand des definierten Vokabulars in RDF-Tripel transformiert. Für jede Schülerinstanz wird dabei eine eindeutige URI erzeugt, die mit den zugehörigen Eigenschaften (Vorname, Nachname, Geburtsdatum, Sehhilfe etc.) sowie den verknüpften Fahrstunden über Prädikate wie fahrl:hasDrivingLesson beschrieben wird
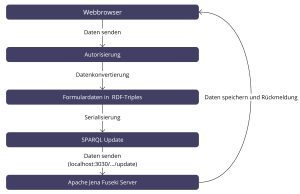
Die so erzeugten Tripel werden in Turtle serialisiert und in eine SPARQL-1.1-INSERT DATA-Anfrage eingebettet. Diese SPARQL-Update-Anfrage wird per HTTP-POST an den Update-Endpunkt des Fuseki-Datasets gesendet (SPARQL 1.1 Update / Graph Store HTTP Protocol). Fuseki verarbeitet die Anfrage, fügt die Tripel in den zugrunde liegenden RDF-Datenspeicher (z. B. TDB2) ein und bestätigt den erfolgreichen Schreibvorgang an das Backend, das wiederum eine Erfolgsmeldung im Frontend anzeigt.
Datenabruf und Bereitstellung für die App
Für die Anzeige gespeicherter Informationen – etwa der Schülerliste oder der zu einem Schüler gehörenden Fahrstunden – sendet das Backend SPARQL-SELECT-Anfragen an den Query-Endpunkt desselben Fuseki-Datasets. Fuseki führt die SPARQL-Abfrage im Triple Store aus und liefert die Ergebnisse im standardkonformen Format (z. B. JSON oder Turtle) zurück. Im Backend werden diese Rohdaten in ein app-spezifisches JSON-Format transformiert und an das Frontend weitergegeben, sodass sie dort in Listen, Detailansichten oder Übersichten zum Lernfortschritt dargestellt werden können.
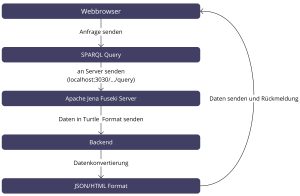
Durch diese klare Trennung von Frontend, Backend und Triple Store entsteht eine lose gekoppelte Architektur: Die FahrMemo-App kommuniziert ausschließlich über standardisierte SPARQL-HTTP-Endpunkte mit Fuseki und kann so perspektivisch auch externe Wissensgraphen einbinden oder von anderen Systemen gemeinsam mitgenutzt werden.