Enterprise Search Engine
Motivation
„Zeitfresser Dokumentensuche: Verbesserungsbedarf in deutschen Büros“ so lautet am 14.07.2017 die Schlagzeile eines Artikels der Fachzeitschrift „ZDNET“. Schon 2017 und wahrscheinlich auch einige Jahre zuvor stieg aufgrund der immer größer werdenden Flut an Dokumenten, wie beispielsweise Formulare oder Anträge, der Zeitaufwand, den Mitarbeiter haben, um aus all diesen Textstücken das Richtige herauszusuchen. Das Neuanlegen eines Dokuments ist oftmals schneller als die Suche nach dem bereits angelegten. Der Autor des Artikels beruft sich dabei auf eine Studie von KYOCERA, die in Kooperation mit dem Portal Statista erstellt wurde. Dabei wurde festgestellt, dass mehr als die Hälfte der Befragten aus dem Bereich Administration/Verwaltung (67%) und Finanzen/Buchhaltung (71%) mehr als eine Stunde (durchschnittlich 119 min) am Tag mit der Suche und Ablage von Dokumenten und Dateien verbringen (Vgl. Abbildung 1).
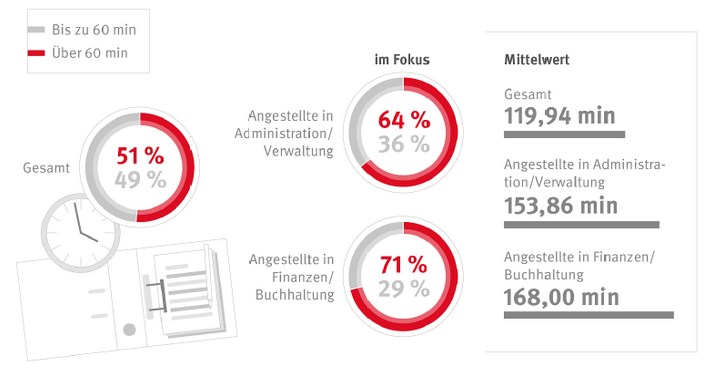
Aufgrund des hohen Zeitaufwandes können sich die Mitarbeiter weniger auf ihre eigentlichen Aufgaben fokussieren. Folgen daraus sind ineffiziente Geschäftsprozesse und resultierende Kosten für den Ausgleich dieser Ineffizienz. Neben dem hohen Zeitaufwand können Unternehmen zusätlich hohe Kosten durch erhöhten Bedarf an IT-Ressourcen entstehen.
Eine Möglichkeit dem genannten Problem entgegenzuwirken ist die Einführung einer Enterprise Search Engine. Eine solche unternehmensweite Suchmaschine verkürzt die Datenzugriffszeiten deutlich und stellt zusätzlich für die Nutzer relevante Informationen bereit.
Überblick
Enterprise Search oder auf Deutsch – unternehmensweite Suche, ist ein Begriff aus dem Forschungsumfeld des Information Retrieval und somit ein Teilgebiet dessen. Sie durchsucht Datenbanken, Unternehmenswebseiten, Intranet, Mailserver und Dateisysteme nach Dokumenten, weiteren Textinhalten und wenn gewünscht auch nach Metadaten von Grafiken und Fotos. Dabei ist es nicht notwendig den prozessualen Ablauf für die Mitarbeiter zu verändern. Das bedeutet, dass Mitarbeiter ihre Dokumente wie gewohnt abspeichern können und sich nicht auf neue Ordnerstrukturen oder Speicherorte einstellen müssen. Diese spezielle Art von Suchmaschinen unterscheidet sich in ihrem Aufbau nicht von herkömmlichen Internetsuchmaschinen. Die wesentlichen 3 Bestandteile einer solchen Websuchmaschine sind Crawler oder Crawling Engine, Indexer und Query Engine, welche für die Beschaffung, Aufbereitung und Bereitstellung der Ergebnisse zuständig sind.
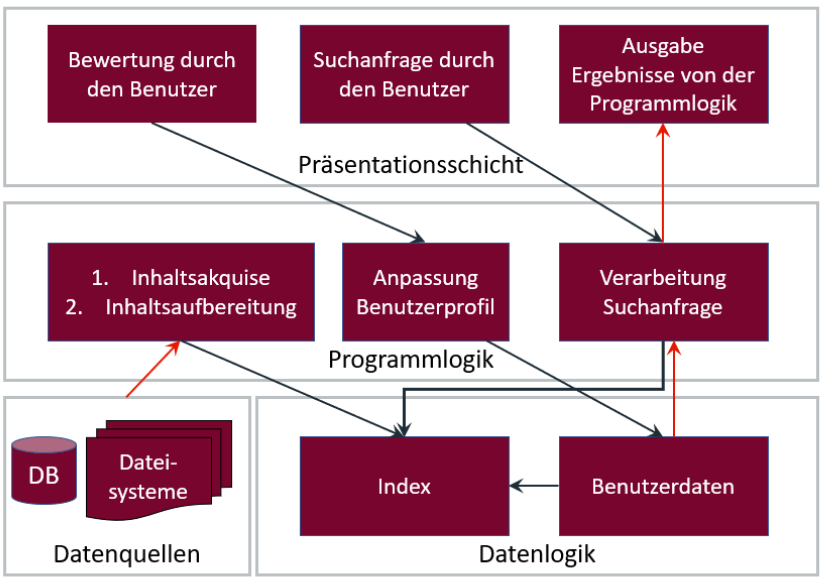
Quelle: Eigene Darstellung angelehnt an Lewandowski, Dirk(hrsg) (2009), S. 340
Abbildung 2 zeigt, wie Enterprise Suchmaschinen aufgebaut und die internen Abläufe bei einer Suchanfrage geregelt sind. Nach Eingabe der Suchanfrage durch den Anwender wird diese verarbeitet und mit Metadaten, unter anderem mit Benutzerdaten, angereichert. Anschließend werden die benötigten Informationen aus dem Index gezogen. Dieser besteht aus aufbereiteten Daten, welche bei der Inhaltsakquise aus verschiedenen Datenquellen gezogen wurden. Das Speisen des Index mit Daten ist ein von der Suche durch den Anwender abgekoppelter zyklischer Prozess. Die gesammelten Datensätze werden dem Suchenden in Form einer Liste präsentiert, dieser kann dann die Ergebnisse bewerten und die Suche gegebenenfalls anpassen. Die Bewertung des Benutzers löst eine Anpassung des Benutzerprofils aus, welche dann in der Datenlogik unter Benutzerdaten abgespeichert wird.
Elastic Search
Im Jahr 2010 veröffentlichte Shay Banon die erste Version seiner Open Source Enterprise Suchmaschine Elasticsearch. Realisiert ist die Suchmaschine in Java als Webservice und bietet somit eine plattformunabhängige Anwendung basierend auf der Softwarebibliothek Lucene von Apache. Die Kommunikation mit Elasticsearch funktioniert entweder direkt in der Programmiersprache Java über zwei integrierte Clients (Node-Client und Transport Client) oder durch verschiedene andere Programmiersprachen über eine RESTful API mithilfe von JSON (JavaScript Object Notation) und http. Die Systeminfrastruktur kann sowohl als Stand-Alone System oder verteilt auf vielen verschiedenen Servern realisiert werden.
Elasticsearch ist dokumentenorientiert, das bedeutet, dass bei dieser Anwendung, anders als üblich, gesamte Dokumente und Objekte abgespeichert und indexiert werden. Dies ermöglicht das Suchen gesamter Dokumente und erspart das Aufschlüsseln der Metadaten in verschiedene Spalten einer Datenbanktabelle. Zudem müssen die Dokumente nicht jedes Mal aus diesen Informationen der Datenbank rekonstruiert werden. Zur Serialisierung der Dokumente verwendet die Suchmaschine JSON, welches trotz komplexer Objekte die Konvertierung und die anschließende Indizierung einfacher macht als ein äquivalenter Prozess mit Tabellenstruktur. Zusätzlich existieren JSON Bibliotheken für nahezu alle Programmiersprachen, welche die Umwandlung, egal welcher Datenstruktur, in dieses Format ermöglichen. Zur Speicherung der Dokumente nutzt Elasticsearch einen Index in Form invertierter Listen.
Beispiel
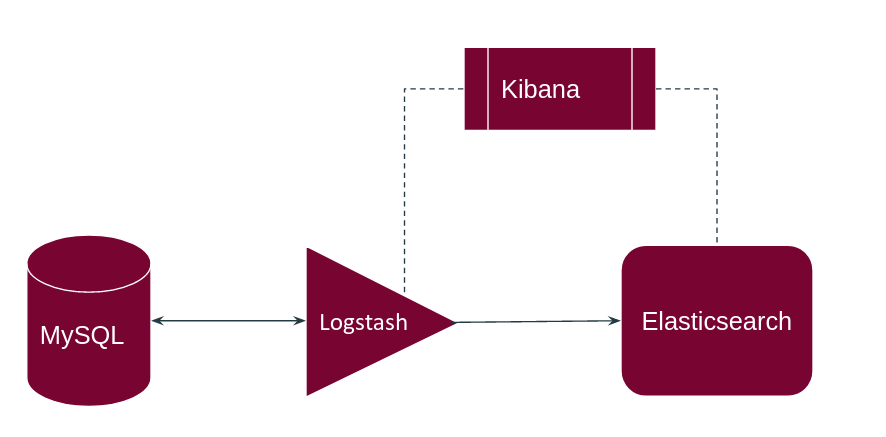
In unserem Beispiel haben wir uns für die Realisierung mit dem Elastic Stack bestehend aus Elasticsearch, der Grafischen Oberfläche Kibana und dem Datenanbindungstool Logstash entschieden. Alle Komponenten, die in Abbildung 3 zu sehen sind laufen dabei auf einer separaten Dockerinstanz arbeiten jedoch zusammen. Logstash dient in diesem Fall dazu die Daten aus unserer Beispieldatenbank (MySQL) zu akquirieren und anzureichern, um sie anschließend mit Elasticsearch zu synchronisieren. Die von Logstash gesammelten Daten werden dann von Elasticsearch Indexiert und durchsuchbar gemacht. Die grafische Oberfläche Kibana dient der Administration von Logstash und Elasticsearch. Hier werden Metriken und Monitoring-Daten visualisiert, Log-Daten können analysiert werden und Anfragen können für in den Devtools getestet werden Elasticsearch ist dabei über eine REST-Api erreichbar.
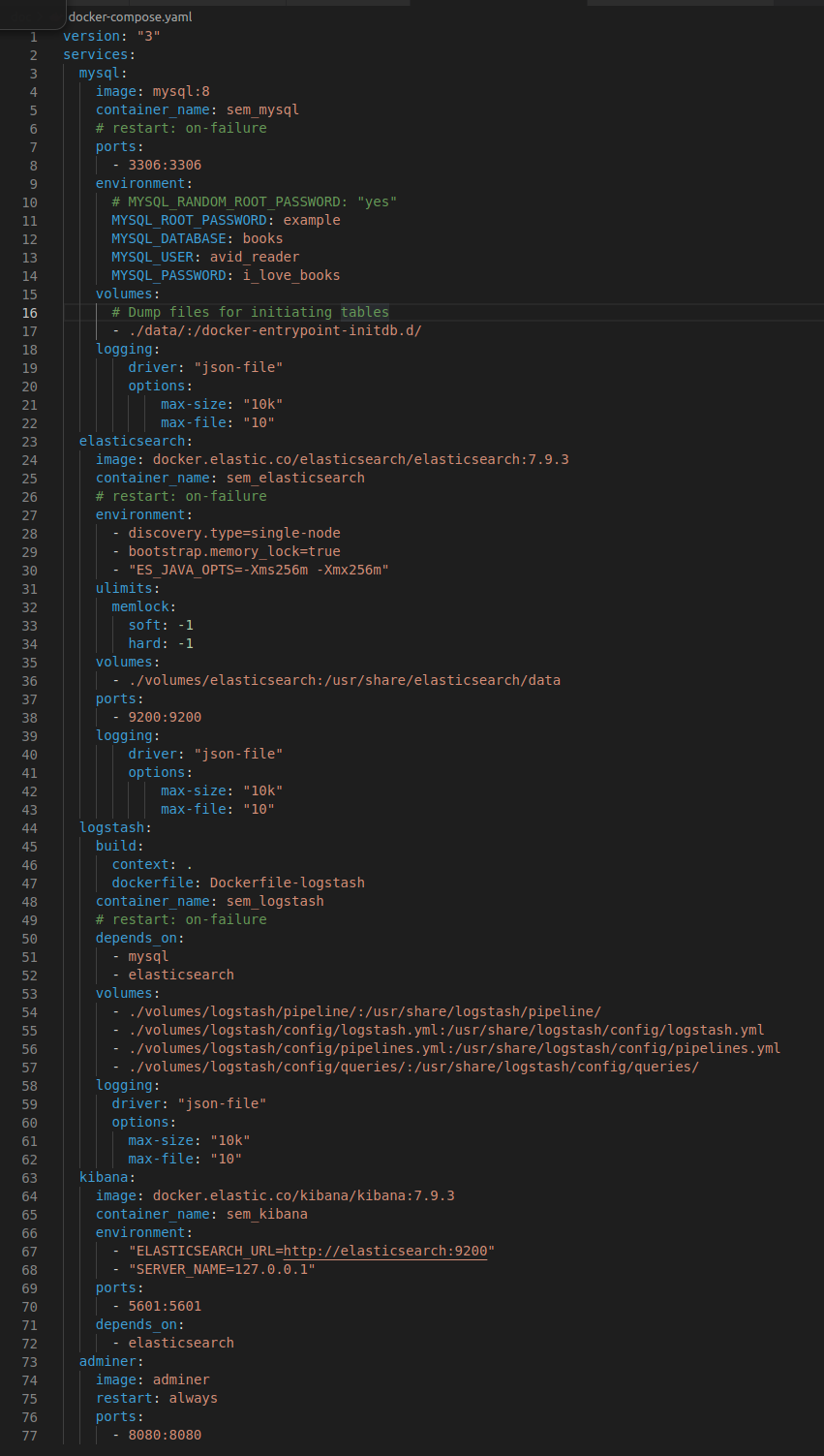
In unserem Beispiel haben wir Elasticsearch über Loigstash mit einer Buchdatenbank verbunden.
Eine Anfrage an Elastic könnte dann z.B. so aussehen:
GET books/_search?size=3 //max. 3 Ergebnisse anzeigen
{
"query": {
"multi_match": {
"query": "Adventures Mark Twain", //Suchbegriffe
"fields": ["title", "authors"] //zu durchsuchende Felder
}
}
}
Das Ergebnis könnte dann folgendermaßen aussehen:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 13, //insgesamt 13 Suchergebnisse gefunden
"relation" : "eq"
},
"max_score" : 8.961069, //Score des besten Ergebnis
"hits" : [
{ //Suchergebnis mit dem höchsten Score
"_index" : "books",
"_type" : "_doc",
"_id" : "9781402726002",
"_score" : 8.961069,
"_source" : {
"title" : "The Adventures of Huckleberry Finn",
"publication_date" : "2006-10-28T00:00:00.000Z",
"isbn" : "9781402726002",
"authors" : "Mark Twain/Scott McKowen/Arthur Pober"
}
},
{
"_index" : "books",
"_type" : "_doc",
"_id" : "9781426423703",
"_score" : 6.2986403,
"_source" : {
"title" : "The Adventures of Sally",
"publication_date" : "2008-05-29T00:00:00.000Z",
"isbn" : "9781426423703",
"authors" : "P.G. Wodehouse"
}
},
{
"_index" : "books",
"_type" : "_doc",
"_id" : "9780964366565",
"_score" : 5.6587152,
"_source" : {
"title" : "Lo único que no podrás hacer en el cielo",
"publication_date" : "2007-03-01T00:00:00.000Z",
"isbn" : "9780964366565",
"authors" : "Mark Cahill"
}
}
]
}
}
Über ein Score wird bewertet wie gut Suchanfrage und Ergebnis übereinstimmen. Der Einfluss bestimmter Worte auf den Score kann auch angepasst werden, so werden in der Regel Füllwörter wie „und“, „oder“, sowie Artikel, geringer gewertet. Über die API lässt sich dann auch ein Frontend für die Suche implementieren, damit diese z.B. auf Webseiten eingebunden werden kann.
Vortragsfolien
Quellen
- Schindler, Martin (2017): Zeitfresser Dokumentensuche: Verbesserungsbedarf in deut-schen Büros, 14.07.2017, abgerufen am 19.12.2020, http://www.si-licon.de/41652561/zeitfresser-dokumentensuche-verbesserungsbedarf-in-deut-schen-bueros/.
- KYOCERA Document Solutions Deutschland GmbH und Statista Online-Befragung (2018): Studie_Dokumente_gesucht_gefunden, 2018.
- Lewandowski, Dirk(hrsg) (2009): Handbuch Internet-Suchmaschinen. Nutzerorientierung in Wissenschaft und Praxis. 1. Aufl., Heidelberg, Neckar, 2009, ISBN: 978-3-89838-607-4.
- Lewandowski, Dirk (2015): Suchmaschinen verstehen, 2015, ISBN: 978-3-662-44013-1.
- Wendl, Christoph (2019): DMS versus Enterprise Search: Suchmaschinen für den Unternehmenseinsatz heben den Umgang mit Dokumenten aufein neues Level
- You Know, for Search, 08.02.2010, abgerufen am 21.01.2021, https://www.elas-tic.co/de/blog/you-know-for-search.
- You Know, for Search! (inc), 13.07.2012, abgerufen am 21.01.2021, https://www.elastic.co/de/blog/you-know-for-search-inc
- Document Oriented | Elasticsearch: The Definitive Guide [2.x] | Elastic, 18.06.2020, abgerufen am 21.01.2021, https://www.elastic.co/guide/en/elas-ticsearch/guide/2.x/_document_oriented.html.
- Indexing Employee Documents | Elasticsearch: The Definitive Guide [2.x] | Elas-tic, 18.06.2020, abgerufen am 21.01.2021, https://www.elastic.co/guide/en/elas-ticsearch/guide/2.x/_indexing_employee_documents.html.