Data Mining – Driverless AI
Bedeutung von Data Mining
Begriffsdefinition und Abgrenzung
„The fruits of knowledge growing on the tree of data are not easy to pick.“
– Frawley et al., Knowledge Discovery: An Overview, 1992
Data Mining beschreibt die „Extraktion implizit vorhandenen, nicht trivialen und nützlichen Wissens aus großen […] komplex strukturierten Datenbeständen“. Unter Wissen versteht man hierbei ein Muster, das „interessant ist und mit ausreichender Sicherheit tatsächlich existiert“ (Bissantz et al., 2009). Angetrieben von sinkenden Preisen für Speicherplatz und dem Aufkommen des Internets, wächst die Diskrepanz zwischen der Menge an generierten Daten und dem aus den Daten gewonnenen Wissen kontinuierlich. Data Mining versucht, diese Lücke wieder zu schließen.
Obwohl sich Data Mining in den letzen Jahren als ein wesentlicher Trend in der IT etabliert hat, kommen beim Data Mining längst etablierte Verfahren zum Einsatz. Im Kern bedient sich Data Mining nämlich vieler Methoden aus der Statistik. Allerdings beschreibt Data Mining darüber hinausgendend, den ganzen Prozess von Datenakquise, über Datenaufbereitung, der Mustererkennung bis hin zur benutzerfreundlichen Präsentation der Erkentnisse und meist einer konkreten Handlungsempfehlung.
Data Mining im Unternehmen
Die renommierte Unternehmensberatung McKinsey kommt im Rückblick auf das Jahr 2021 zu dem Schluss, dass Unternehmen, die eine effektive Datenanlysestrategie verfolgen, im Schnitt eine 1,5 Mal höhere Wachstumsrate aufweisen.
Potenzielle Use Cases von Data Mining in den unterschiedlichen Bereichen der Unternehmenspyramide sind z.B.:
- Target Marketing – Vorhersage & Unterbreitung möglichst erfolgsversprechender und kundenspezifischer Produktvorschläge („Dieses Produkt wurde häufig zusammen gekauft mit …“) (Vertrieb / Marketing – operative Ebene)
- Customer Churn Prediction – Filtern von Kunden, welche die Vertragsbeziehung vermutlich bald beenden könnten & gezieltes Anwenden von Kundenzufriedenheitsmaßnahmen (Rabatte, Boni, Gutscheine etc.) (Vertrieb / Marketing – operative Ebene)
- Umsatzprognose – Vorhersage des zu erwartenden Umsatzes auf Basis relevanter Daten (Umsatz in Vorperioden, Materialaufwand, Abschreibungen, Konjunktur, Prognosefehler etc.) (Rechnungswesen – Management-Ebene)
- Key Value Indikatoren in Produktionsprozessen – Analyse & Monitoring von Kennzahlen der Produktion (Wartezeiten, Umlaufzeiten, Durchlaufzahlen etc.) (Fertigung / Produktio – Management-Ebene)
Überblick Data Mining Software
Programmiersprachen
Grundsätzlich kann Data Mining mit jeder beliebigen Programmiersprache betrieben werden. Hieraus ergibt sich die größte Flexibilität, da beliebiger Code zur Verarbeitung der Daten geschrieben werden kann. Darüber hinaus ist die Nutzung beliebiger verfügbarer Programmbibliotheken möglich. Idealerweise sollte eine Programmiersprache gewählt werden in deren Ökosystem bereits nützliche Bibliotheken existieren. Folgend sollen zwei Beispiele Genannt werden.
Python
Python ist eine auf vielen Plattformen verfügbare höhere Programmiersprache welche die Pradigmen der objektorientierten, aspektorientierten und funktionalen Programmierung erlaubt. In Python kann der Anwender auf eine Vielzahl von Bibliotheken die Funktionalität für Data Mining implementieren zurückgreifen. Beispiele hierfür wären pandas für Datenanalyse/-manipulation, scikit-learn für Machine Learning und matplotlib für Visualisierung.
Darüber hinaus existieren spezialisierte Werkzeuge wie Jupyter Notebook zur bequemeren Auswertung und Organisation kleiner Codeschnipsel für Analysen sowie Python-Distributionen wie Anaconda welche eine kuratierte Sammlung an Paketen für Datenanalyse und Data Mining bereitstellen.
R
R ist eine Programmiersprache für statistische Berechnungen und Visualisierungen welche als Designziel die Nutzbarkeit für Datenanalyse hat. Sie besitzt somit bereits einige eingebaute Funktionalität zur Analyse und Visualisierung von Daten. Zusätzlich existieren auch hier Pakete welche weitere Funktionalität beisteuern.
Spezialisierte Software
Für statistische Analysen existiert Software für statistische Analysen wie matlab oder Scilab.
Darüber hinaus existiert spezialisiertere Software für den Zweck des Data Mining. Diese bietet dann Funktionalität zur weiteren Verarbeitung der Daten, wie Workflows, Klassifikation und weitere Möglichkeiten des Machine Learning. Der Vorteil ist die einfachere Zugänglichkeit der Funktionalität da meist keine – oder nur spezifische – Programmierkenntnisse nötig sind, sowie teils bessere Möglichkeiten der Integration in einem betrieblichen Kontext.
Nachfolgend sollen einige Beispiele erwähnt werden:
WEKA
WEKA – oder Waikato Environment for Knowledge Analysis – ist ein quelloffenes, umfangreiches, plattformunabhängiges Data Mining Softwarepaket, es wird entwickelt an der University of Waikato, New Zealand.
WEKA bietet verschiedene GUI-Module: Explorer, Experimenter, KnowledgeFlow und simple CLI. Hierbei bietet der Explorer Funktionalität wie Klassifikation (Machine Learning) und Visualisation. Ein Import der Daten aus CSV-Dateien und Datenbanken (via JDB) ist möglich.
Im Knowledge Flow lassen sich Workflows definieren die verschiedene Einzelfilter und Klassifikatoren miteinander verknüpfen.
Die Funktionalität lässt sie hierüber hinaus mittels Plugins erweitern.
Orange
Orange ist eine umfangreiche quelloffene Software zur Datenanalyse. Es wird an der University of Ljubljana entwickelt. Es bietet eine umfassende grafische Oberfläche, in der Workflows zur Verarbeitung von Daten erstellt werden können. Diese Workflows verknüpfen einzelne Widgets miteinander. Diese Widgets liefern wiederum einzelne Funktionalitäten wie einen Datenimport oder verschiedene Werkzeuge für Machine Learning. Darüber hinaus existieren Widgets deren Verhalten per Python frei definiert werden kann.
Umgekehrt ist Orange auch per Python API-steuerbar und kann in übergreifende Arbeitsabläufe integriert werden.
SAS
SAS ist ein umfassendes Statistiksoftwarepaket welches Möglichkeiten weit über Datenanalyse und Data Mining hinaus bietet. So existieren auch Komponenten für Qualitätskontrolle (SAS/QC) und zur Analyse von Klinischen Studien (SAS/PH). Für die Zwecke des Data Mining existieren die Komponenten SAS/INSIGHT und Enterprise Miner.
SAS/INSIGHT ist eine Klassische Anwendung, sie erlaubt die Verarbeitung und Visualisierung von Datensätzen.
SAS Enterprise Miner ist eine Client-Server basierte Anwendung. Es erlaubt eine Integration mit im betrieblichen Umfeld eingesetzter Standardsoftware wie zum Beispiel Microsoft Excel oder verschiedene Datenbanksysteme. Es lassen sich basierend auf eingegangenen Daten automatisch mittels prädiktiver Analyse Vorhersagemodelle erstellen um z.B. die Wahrscheinlichkeit von Ereignissen vorherzusagen.
SAS ist Proprietäre Software, Preise werden nur auf Anfrage herausgegeben. Es existiert allerdings eine für Bildungszwecke kostenlos nutzbare Cloudbasierte Webversion von SAS Studio und SAS Viya.
H2O Driverless AI
Wieso H2O Driverless AI?
Das Wirtschaftsmagazin Forbes berichtet, dass in erstaunlich vielen Unternehmen das Thema Data Mining nach wie vor vernachlässigt wird. Nicht zuletzt liegt das daran, dass sich nicht jedes Unternehmen den Luxus eines eigenen Data Science Teams leisten kann. Die Firma h20 hat daher mit Driverless AI ein Produkt entwickelt, dass viele der Aufgaben eines Data Scientists automatisiert übernehmen können soll. So könnten auch kleinere und mittlere Unternehmen von den Vorteilen einer effektiven Datenanalysestrategie profitieren. Das Potential einer solchen Lösung wäre enorm, weswegen wir uns entschieden haben, Driverless AI näher zu beleuchten.
Installation und Verwendung von Driverless AI
Installation
Die verschiedenen Installationsmöglichkeiten sind in der Dokumentation aufgelistet. Driverless AI lässt sich auf Linux, Windows und macOS und als Cloud Lösung in Amazon AWS, Microsoft Azure und Google Cloud installieren. Während die Installation auf consumer Hardware zwar grundsätzlich möglich ist, sind die Anforderungen an CPU und GPU wegen der anspruchsvollen Machine Learning Tasks recht hoch. Möchte man Driverless AI auf eigener Hardware installieren, bietet sich die Installation über Docker an.
Dozenten und Studierende können über das academic program von H2O kostenlos eine 6-monatige Lizenz beziehen, allerdings ist der Prozess dafür recht langwierig. Um einen Eindruck von der Software zu gewinnen oder die hier vorgestellten Experimente zu reproduzieren, reicht auch das Test Lab von H2O („Aquarium“). Man hat hier die Möglichkeit, eine Instanz von Driverless AI in der Cloud zu starten, die nach zwei Stunden automatisch wieder gelöscht wird. Dabei gehen alle Daten verloren; für einen ersten Eindruck reicht die Zeit aber allemal. Es finden sich hier auch einige interessante weiterführende Erläuterungen zum Thema Data Mining und Machine Learning und vorgefertigte Labs mit zugehörigen Tutorials.
Alternativ kann Driverless AI über die 14-tätige Testversion der H2O AI Cloud getestet werden. Die AI Cloud beinhaltet noch weitere Softwarelösungen, für uns ist an dieser Stelle aber nur Driverless AI von Interesse. Um Driverless AI innerhalb der AI Cloud zu nutzen, muss nach erfolgter Registrierung zunächst auf den Tab „My AI Engines“ gewechselt werden.

Hier kann eine neue Driverless AI Instanz erzeugt und gestartet werden. Die Default Werte können beibehalten werden.

Beispielhafter Use Case
Problemformulierung

Die Abwanderungsquote (customer churn rate) beschreibt den Anteil der Kunden, die aufhören einen Dienst oder ein Produkt zu nutzen. Sie ist eine zentrale Metrik für die Kundenzufriedenheit und kann vom Marketing genutzt werden, um Kundenrückgewinnungsmaßnahmen zu ergreifen. Das Subskriptionmodell hat sich längst als Vertriebsstrategie in nahezu allen Geschäftsfeldern etabliert. Gleichzeitig ist es heute einfacher denn je, einen schnellen Vergleich zwischen Anbietern durchzuführen und sich für die beste Option zu entscheiden. Das Risiko für ein Unternehmen, einen Kunden zu verlieren, ist dementsprechend hoch.
Die Kosten dafür, einen neuen Kunden zu gewinnen sind etwa fünf mal so hoch, wie die Kosten dafür, einen bestehenden Kunden zu halten. Es ist daher von großem Interesse, frühzeitig erkennen zu können, bei welchen Kunden die Wahrscheinlichkeit einer Abwanderung am höchsten ist. Diese Vorhersage nennt sich customer churn prediction. Die Relevanz der Treffischerheit dieser Vorhersage ist in der Grafik dargestellt: Ein Kunde, dessen Abwanderung vorhergesehen wurde, kann möglicherweise durch entsprechende Anreize oder Hilfestellung gehalten werden. Eine Kunde, dessen Abwanderung nicht vorhergesehen wurde, ist i.d.R. für das Unternehmen verloren.
Oft lässt sich aus dem Verhalten der Kunden bereits vor der Kündigung ablesen, wie zufrieden sie mit dem Produkt sind. Wir wollen daher im Folgenden versuchen, mit Hilfe von Driverless AI, die Unzufriedenheit der einzelnen Kunden – und damit die Wahrscheinlichkeit einer Abwanderung – aus einem Datensatz abzuleiten.
Datenbasis
Bei Data Mining geht es um automatisierte Datenauswertung. Meistens werden die Daten durch mehrere verschiedene Machine Learning Algorithmen ausgewertet und visualisiert. Um ein passendes Machine Learning Modell zu erstellen werden viele Daten benötigt, an denen das System lernen kann. Bei diesem Vorgehen ist das „supervised learning“ verbreitet, es so viel heißt wie „überwachtes lernen“. Hierbei werden die Daten, die gelabelt sein müssen, in eine Trainingsgruppe und eine Kontrollgruppe aufgeteilt. Im ersten Schritt wird der Algorithmus mit den Trainingsdaten trainiert. Dabei sind alle Features der Daten für den Algorithmus bekannt. So kann er sich ein Bild machen, aus welchen Zusammenhängen welche Schlussfolgerungen gezogen werden können. Im zweiten Schritt wird der Algorithmus mit den Kontroll- /Testdaten geprüft. An dieser Stelle sind die zu schlussfolgernde Features ausgeblendet und der Algorithmus muss diese anhand seiner „Erfahrung“ vorhersagen. Diese Vorhersagen werden mit den tatsächlichen Ergebnissen verglichen. So kann die Wahrscheinlichkeit einer richtigen Vorhersage bestimmt werden, sie beschreibt wie gut ein Machine Learning Algorithmus ist.
Das Teilen der Daten in Trainings- und Testdaten muss ebenfalls sinnvoll erfolgen. Es müssen möglichst alle verschiedene Konstellationen in beiden Gruppen vertreten sein. Wären zum Beispiel in der Trainingsgruppe nur Nutzer*innen, die von dem Produkt abgewandert sind, kann der Algorithmus nur mit sehr kleiner Wahrscheinlichkeit oder garnicht vorhersagen, welche Nutzer bleiben würden. Er kennt keine Datenzusammensetzungen von Nutzer*innen, die er als Beispiel zum Verbleib bei dem Produkt nehmen kann, er kennt nur Abwanderung. Die Aufteilung und Trainings- und Testdaten ist so wichtig, damit der Algorithmus nicht auf einen Datensatz „overfitted“ ist, also zu sehr angepasst ist. Würde man alle Daten sowohl als Trainings als auch als Testdaten verwenden, lernt der Algorithmus nur die Fälle in den Daten „auswendig“, anstatt einen allgemeinen Lösungsansatz zu finden. Verwendet man diesen „overfitted“ Algorithmus auf neue Daten würde er sehr schlechte Ergebnisse liefern.
Relevant ist auch die Qualität von den Daten. Es ist notwendig die Rohdaten zu bereinigen. Sie dürfen keine Ausreißer, keine Lücken, keine Dopplungen, keine Unregelmäßigkeiten, keine falsch gemessenen oder abgelaufenen Daten enthalten. Anderenfalls könnte sich der Algorithmus z.B. zu sehr auf einen Ausreißer fokussieren und so keine zuverlässigen Ergebnisse liefern. Ebenfalls müssen die Daten auf den Usecase passen. Will man eine churn prediction für Telefonverträge machen, sind zum Beispiel Daten wie allgemeine Kundeninformationen, demographische Daten oder Vertragsdaten relevant. Daten wie z.B. das Wetter oder die Farbe der Autos der Kund*innen sollte auf die Abwanderung bei einem Telefonvertrag jedoch keinen Einfluss haben und verbessern somit den Datensatz nicht. Demnach ist nicht immer die Menge der Features ausschlaggebend für einen guten Datensatz, sondern eine möglichst hohe Anzahl an auf den Usecase passenden Features.
Zusammenfassend lässt sich sagen, dass bei Data Mining die Qualität der Analyseergebnisse mit der Qualität der verwendeten Daten sowie ihrer Aufteilung in Trainings- und Testdaten steht und fällt.
Als Basis für unser Experiment nutzen wir einen von IBM generierten Datensatz (Download) eines fiktiven Telekommunikationsanbieters. Dieser Datensatz beinhaltet über 7000 Einträge mit jeweils 20 Features plus Response-variable (churn). Er enthält mehrere demographische Daten, allgemeine Kundeninformationen und Services Informationen sowie die Abwanderung. Diese Menge an sauberen und auf den Usecase passenden Daten ist eine gute Grundlage für maschinelles Lernen.
Wir hätten gerne mit Studierenden Daten der HTWK gearbeitet und haben dafür bei der Datenschutzbeauftragten nachgefragt. Dabei hat sich herausgestellt, dass wir nur bereits anonymisierten Daten verwenden dürften, wie z.B. die Daten der Evaluation. Diese Daten hätten jedoch kein hilfreiches Beispiel zum Vorhersagen geboten, weshalb wir diese Daten nicht weiter angefragt haben.
Telco customer churn data set:
21 Features (inkl. ID und Churn)
Analysen in Driverless AI
Zunächst wollen wir Driverless AI mit unseren Daten bekannt machen. In der Testversion können wir unsere Daten entweder als Datei hochladen oder einen Amazon S3 Speicher verbinden. In der Vollversion kann bspw. auch eine SQL-Datenbank, ein Azure Blob Storage oder ein Snowflake Data Warehouse angebunden werden (Vollständige Übersicht). Wir laden unsere Daten als csv Datei hoch.

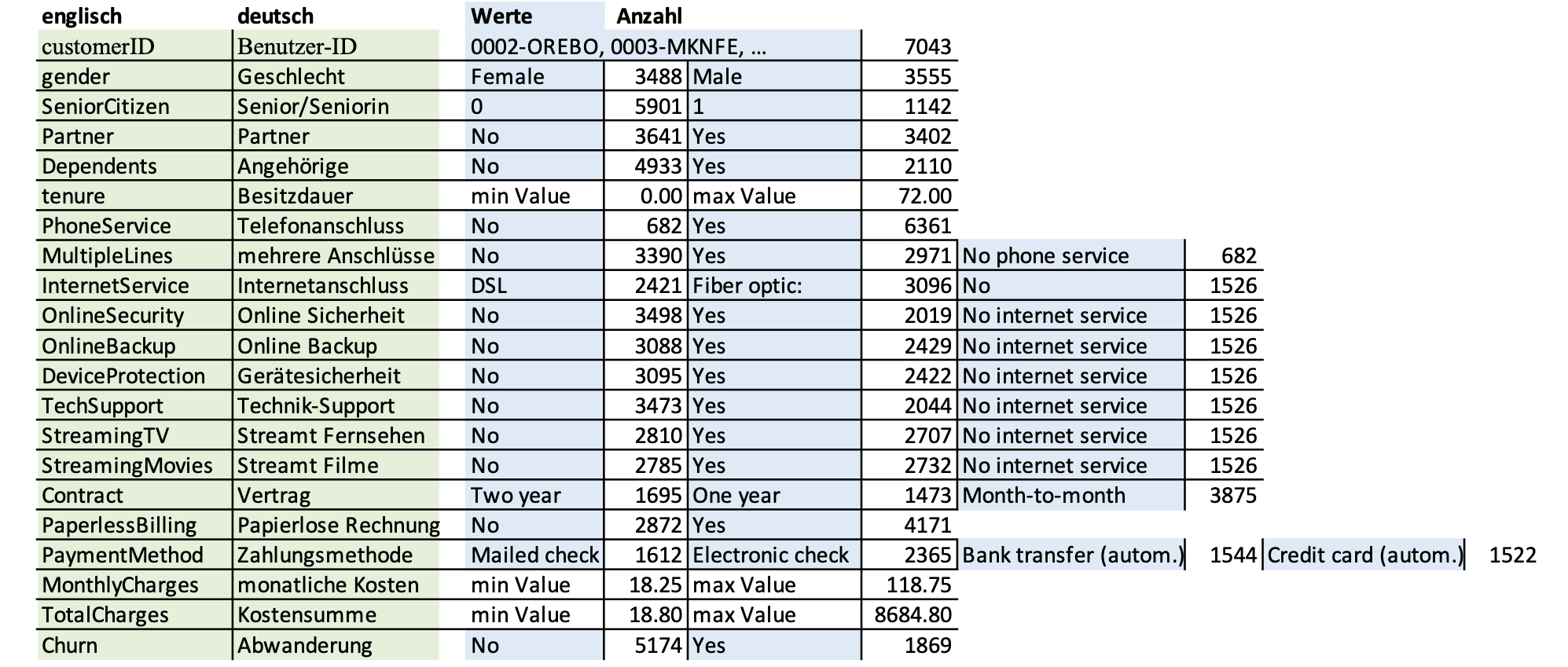
Das Splitten des Datensets in Train- und Test-Set, das üblicherweise vom Anwender selbst vorgenommen wird, übernimmt Driverless AI automatisiert. Man teilt dem Programm lediglich mit, welches Feature später vorhergesagt werden soll und wie das Größenverhältnis von Train- und Test-Set sein soll. Driverless AI sorgt dafür, dass auch die seltener vorkommende Ausprägung des vorherzusagenen Features ausreichend oft im Test-Set vorkommt.
Mit einem Klick auf „Details“ kann das Datenset inspiziert werden. Man bekommt für jedes Attribut die Verteilung der jeweiligen Attributwerte, Informationen über fehlende Werte und für numerische Features zusätzlich statistische Kennzahlen wie Min- und Max-Wert und Mittelwert angezeigt.

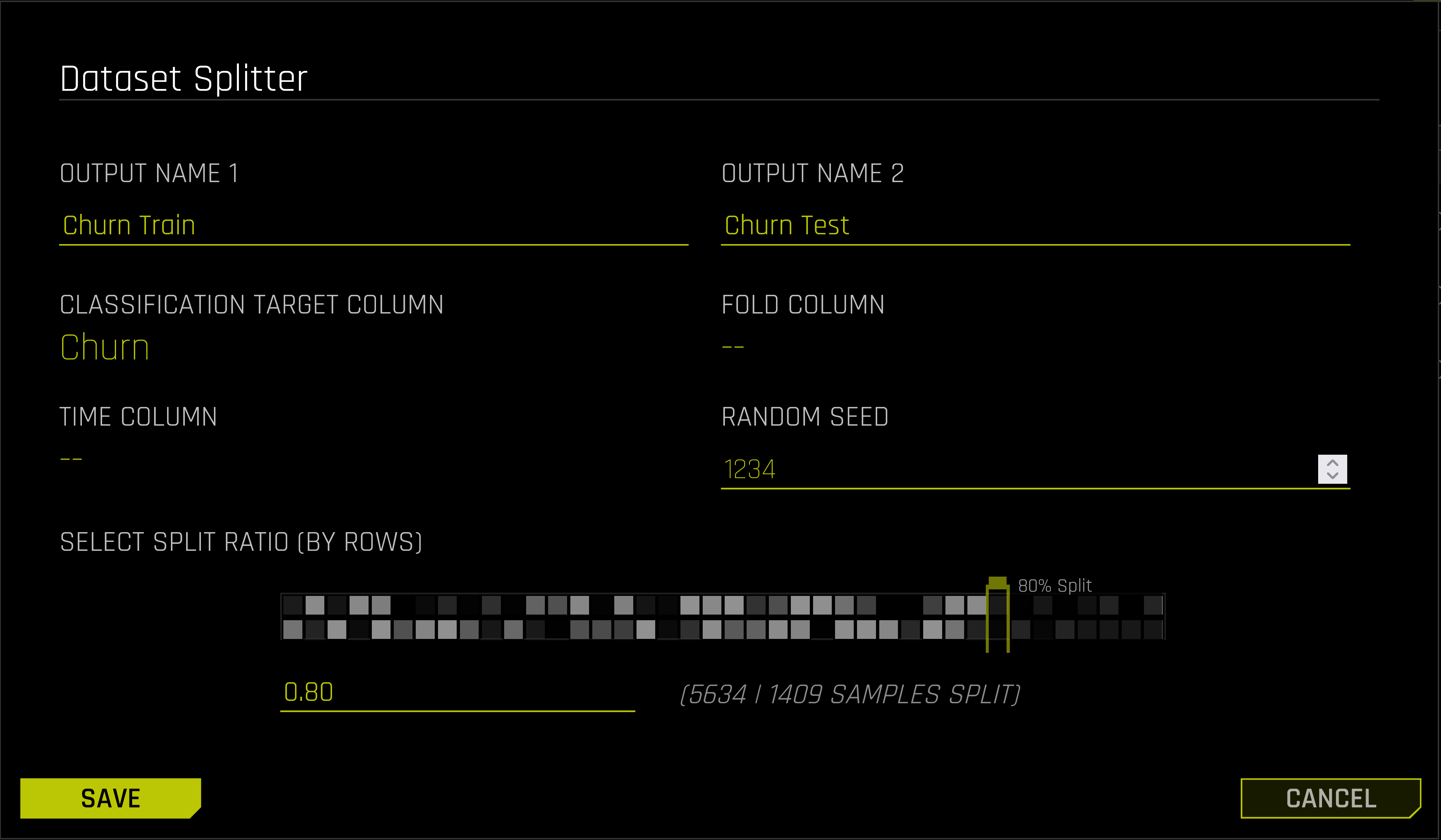
Nun kann unter dem „Projects“ Tab ein neues Projekt angelegt werden.Wir verlinken unser zuvor erstelltes Train- bzw. Test-Set. Rechts sehen wir eine Auflistung aller Experimente, die wir im Zuge dieses Projekts durchgeführt haben. Sind mehrere Experimente erstellt worden, lasse sich diese auf einen Blick hinsichtlich relevanter Kennzahlen vergleichen.
Das Erstellen eines neuen Experiments gestaltet sich sehr einfach. Nach einem Klick auf „New Experiment“ sehen wir folgende Maske. Als „Target Column“ wählen wir „Churn“. Driverless AI erkennt automatisch, dass es sich hierbei um ein Klassifikationsproblem handelt (also um die Entscheidung „Churn – Ja oder Nein“. Ein Beispiel für Regression wäre z.B. die Ermittlung eines optimalen Produktpreises). Zusätzlich haben wir drei Faktoren, die wir manipulieren können: Accuracy, Time und Interpretability. Eine höhere Accuracy bedeutet in der Regel eine höhere Präzision der Ergebnisse. Intuitiv würde man hier wohl den höchstmöglichen Wert wählen, allerdings entsteht dann das Risiko des sogenannten Overfittings. Der Algorithmus könnte also u.U. zu exakt die Trainingsdaten modellieren und würde Datenpunkte, die auch nur etwas von den Trainingsdaten abweichen, falsch klassifizieren. Time bezieht sich auf die Laufzeit des Experiments, die je nach verwendeten Algorithmen und Länge der Optimierungsphase zwischen wenigen Minuten und mehreren Stunden oder sogar Tagen varriieren kann. Ein kleinerer Wert steht für eine kürzere Experimentlaufzeit. Ein höherer Wert für Interpretability sorgt dafür, dass nur solche Algorithmen zum Training verwendet werden, deren Ergebnisse sich im Nachhinein auch intuitiv erklären lassen. Dies spielt z.B. bei der automatisierten Bearbeitung von Kreditanträgen oder medizinischen Use Cases eine große Rolle. Sind alle Einstellungen gesetzt, kann das Experiment gestartet werden.

Links und rechts oben sehen wir die Experimenteinstellungen nochmal aufgelistet. Oben in der Mitte sehen wir den aktuellen Fortschritt des Experiments. Driverless AI trainiert automatisch viele verschiedene Modelle in verschiedenen Konfigurationen und Kombinationen (Ensemble Learning). Unten rechts sehen wir die ROC Kurve des aktuell best performenden Modells. Sie gibt Auskunft über die Genauigkeit des Modells. Optimal wäre eine Kurve, die durch den Ursprung oben links verläuft. Je näher sie sich der gestrichelten diagonalen Linie nähert, desto schlechter. Ein solches Modell hätte nur eine Treffsicherheit von 50%. Der AUC (area under the curve) Wert ist das bestimmte Integral der ROC Kurve. Je näher er an dem Wert 1 liegt, desto besser. Unten in der Mitte sehen wir eine Vorschau auf die sog. Variable Importance. Wir sehen also, welche Features die höchste Aussagekraft in unserem aktuellen Modell haben.

Driverless AI merkt automatisch, wann keine weitere Verbesserung der Ergebnisse zu erwarten ist und bricht an diesem Punkt selbstsändig ab. Bei uns war das nach etwa 6 Minuten der Fall. Wir haben jetzt die Möglichkeit, Einsicht in das trainierte Modell zu erhalten. Driverless AI bietet hier eine Vielzahl an Kennzahlen und Visualisierungen an, von denen wir hier einige betrachten wollen.
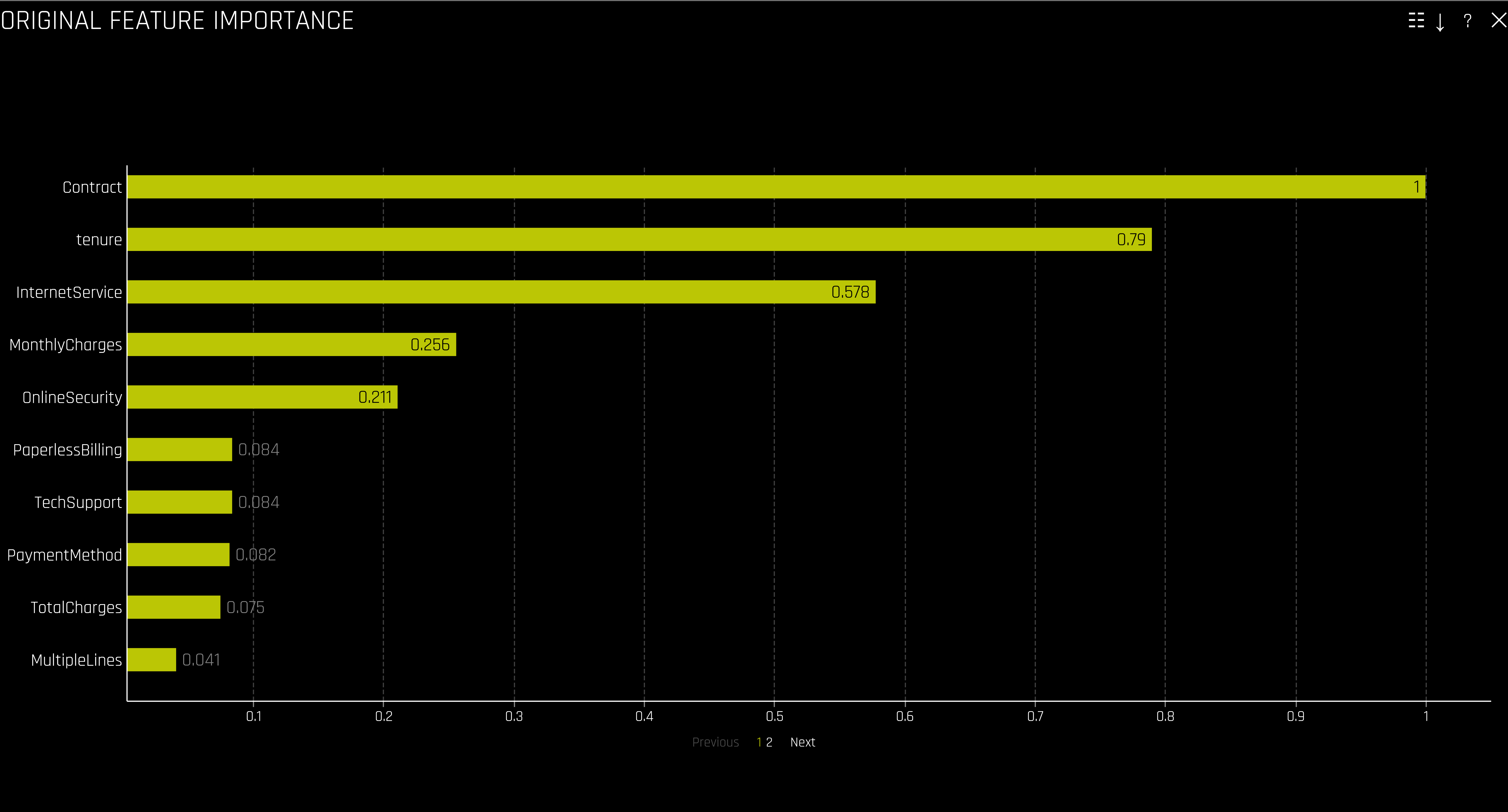
Sinn und Zweck des Experiments war ja nicht nur, ein Modell zu trainineren, das customer churn vorhersagen kann. Wir wollen auch neue Erkentnisse aus den Rohdaten gewinnen und andererseits natürlich auch mit unserem Domainen-Wissen überprüfen, ob die Ergebnisse der Analyse schlüssig sind oder ob vielleicht ein methodischer Fehler begangen wurde. Ein erster guter Anhaltspunkt ist hier die sogenannte Feature Importance. Diese ist normiert auf den Bereich 0 bis 1 und sagt vereinfacht gesagt Folgendes aus: Würden wir unsere binäre Entscheidung nur anhand des am höchsten bewerteten Features festmachen, würden wir im Vergleich zu den anderen Features am seltesten falsch liegen. Hier heißt das also: Wollen wir eine ganz grobe Unterteilung der Kunden hinsichtlich der Gefahr einer Kündigung machen, wäre das Contract Feature am aussagekräftigsten. Zur Erinnerung: Das Contract Feature sagt aus, ob ein Monat-zu-Monat, ein 1-Jahres- oder ein 2-Jahres-Vertrag abgeschlossen wurde.
Jetzt interessiert natürlich, welche der drei Merkmalsausprägungen häufig mit einer Kündigung einhergeht. Hierfür bietet Driverless AI sog. Partial Dependence Plots an. Wir sehen hier für jede Merkmalsausprägung des Contract Features die durchschnittliche churn prediction. Man sieht direkt, die Churn Vorhersage für Month-to-Month Verträge ist signifikant höher als die für 1-Jahres- und 2-Jahres-Verträge. Wir können unsere Aussage von vorhin also präzisieren: Wollen wir eine ganz grobe Unterteilung der Kunden hinsichtlich der Gefahr einer Kündigung machen, lässt sich sagen, dass Kunden mit Verträgen auf monatlicher Basis am ehesten zu einer Kündigung neigen.

Im Feature Importance Plot sehen wir, dass das zweit aussagekräftiste Attribut „tenure“ war – also die Zeit, die der Kunde schon seinen Vertrag hat. Um hier den genauen Zusammenhang von Laufzeit und Kündigungswahrscheinlichkeit zu erfahren, bietet sich ein Plot der Shapley Values an. Uns interessieren an dieser Stelle nur die numerischen Features, die mit aufsteigenden Werten des Features von gelb bis rot eingefärbt sind. Auf der y-Achse sehen wir alle Features aufgelistet. Die x-Achse zeigt den Shapley Value an, mit der 0 in der Mitte. Der Shapley Value ist ein Konzept aus der Spieltheorie und gibt vereinfacht gesagt darüber Auskunft, wie sehr eine bestimmte Merkmalsausprägung eines Features am Gesamtergebnis (also dem Score) beteiligt war. Hat eine bestimmte Ausprägung eines Features den Shapley Value 0, hat das Feature in diesem Fall die Entscheidung weder in Richtung „Churn – Ja“ noch in Richtung „Churn – Nein“ bewegt.
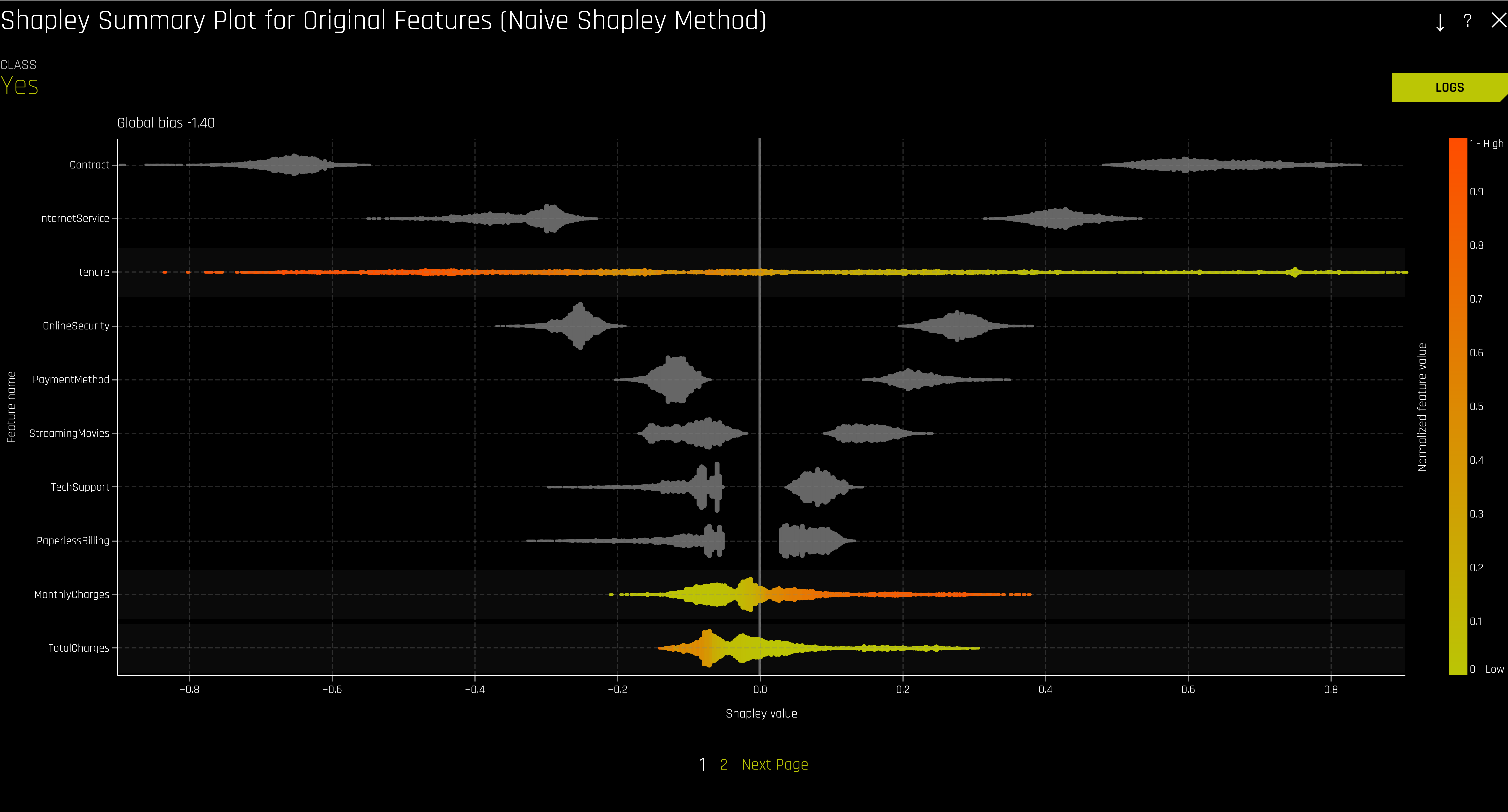
Bei der Shapley Value Methode geht man von einem bestimmten Bias – also einer Art Tendenz – aus. In unserem Fall ist das Bias -1.4 (siehe oben links). Zur Erinnerung: Je weiter der Score (in positiver Richtung) von der 0 entfernt ist, desto eher tendiert das Modell zur Entscheidung „Churn – Ja“. Bildlich gesprochen heißt das also, dass unser Modell zunächst einmal sehr stark Richtung „Churn – Nein“ tendiert. Betrachten wir nun das tenure Feature. Wir sehen, dass je höher der Wert des Features ist – d.h. je länger der Vertrag schon besteht – desto kleiner ist der Shapley Value. Ein hoher Wert von tenure beeinflusst die Entscheidung also in Richtung „Churn – Nein“. Ein niedriger Wert von tenure hat dahingegen einen sehr hohen Shapley Value und beeinflusst die Entscheidung folglich in Richtung „Churn – Ja“. Interessant ist diese Darstellung auch, da man so den „impact“ der verschiedenen Features direkt gegenüber stellen kann. Wir sehen z.B., dass hohe Werte von „Monthly Charges“ einen hohen Shapley Value zugeordnet bekommen haben. Hohe monatliche Ausgaben beeinflussen die Entscheidung also in Richtung „Churn – Ja“. Allerdings ist der Einfluss dieses Features deutlich geringer als der des tenure Features. Folgende These lässt sich also aufstellen: ein Kunde, der erst vor Kurzem seinen Vertrag abgeschlossen hat und nur geringe monatliche Ausgaben hat, ist deutlich eher dazu geneigt zu kündigen, als ein Kunde, der zwar hohe monatliche Ausgaben hat, aber dafür schon seit Langem Kunde ist. Dies bekräftigt im Übrigen nochmal die Anfangsthese und zeigt, wie wichtig es ist, den Kunden langfristig an sich zu binden und einer möglichen Kündigung frühzeitig vorzubeugen.
Deployment
Hat man das Modell inspiziert und möchte es nun in der Produktion einsetzen, bietet Driverless AI mehrere Möglichkeiten. Der einfachste Weg ist es, das Modell als REST Schnittstelle oder AWS Lambda Funktion zu deployen. Unser churn prediction Modell ist über die unten stehende Adresse erreichbar. Alternativ kann bspw. eine Python Scoring Pipeline heruntergeladen werden. Weitere Informationen zum Deployment finden sich hier.

curl \ -X POST \ -d @kunde.json \ -H "x-api-key: EcaW6Hk526549rRhjGj2M9TYqQF8ABVG10Bc3NsH" \ https://mw7j9o1s83.execute-api.eu-central-1.amazonaws.com/test/score
Ein json file zum Testen findet sich hier.
Prozessmodelierung
Ein beispielhafter Prozess zur regelmäßigen Kalibrierung und Anwendung eines Churn-Rate-Prediction-Models im Unternehmen kann wie folgt aussehen:

Aus dem Kundendatenmanagement werden im Rahmen eines Data-Warehousing-Prozesses regelmäßig relevante Kundendaten (Einkäufe, Kundenkontakte, Stammdaten etc.) in ein Kundendaten-Data Warehouse übertragen. Diese Daten werden von H20.AI genutzt, um ein Modell zur Vorhersage der Churn-Rate zu erstellen. Dieses wird turnusmäßig neu kalibriert.
Das Modell kann dann angewendet werden, um regelmäßig Kunden zu kontaktieren, deren Churn Rate hoch ist, um ihnen Rabatte oder Boni anzubieten. Außerdem kann das Modell auch ad-hoc verwendet werden, wenn Kunden inbound Kontakt mit dem Unternehmen aufnehmen, um Maßnahmen zur Steigerung der Kundenzufriedenheit direkt einzuleiten.
Quellen
- McKinsey: B2B commercial analytics: What outperformers do, 2021
- Forbes: Transforming Big Data Initiatives Into AI Insights, 2021
- Nicolas Bissantz et al., Data Mining (Datenmustererkennung), 2009
- Interpretable Machine Learning, Christoph Molnar, 2022
- Data Mining – Concepts, Models and Techniques, Florin Gorunescu, 2011
-
R and Data Mining: Examples and Case Studies, Zhao, Yanchang, 2012
Eine Antwort auf “Data Mining – Driverless AI”