
Elastic Stack
Inhalte
- Motivation
- Inbetriebnahme
- Beats
- Logstash
- Elasticsearch
- Kibana
- Prozessmodellierung
- Vorteile
- Nachteile
- Alternativen
- Fazit & Ausblick
- Referenzen
1. Motivation
Für die Ausrichtung von Geschäftsprozessen sowie die Ressourcenverwaltung betrieblicher Informationssysteme ist die kontinuierliche Erfassung und Verarbeitung von Daten (Business Analytics, BA) im jeweiligen Kontext von großer Bedeutung. Interaktive Analysen (Business Intelligence, BI) erlauben eine Aufschlüsselung von Kennzahlen und darüber einen Einblick in vorangegangene Ereignisse, deren Ursprung und die oftmals nicht auf den ersten Blick erkennbaren Auswirkungen. Ebenso wird eine Abschätzung über die Erfolgswahrscheinlichkeit spezifischer Szenarien möglich, etwa durch Unterstützung von Machine-Learning-Werkzeugen. Der Elastic Stack ist eine Kombination von Open-Source-Projekten zur Verwaltung, Analyse und Visualisierung von Eventdaten und wird im Rahmen von Business Analytics und Business Intelligence eingesetzt. In diesem Kontext bezeichnen Eventdaten jegliche durch den Elastic Stack erhobene und verwaltete Daten, z.B. Log- und Metrikdaten, API-Daten oder Datenbank-Exporte im CSV-Format. Der Elastic Stack wird mit Fokus auf folgende Projekte in diesem Beitrag betrachtet:
- Beats: Erfassung, Verarbeitung und Weiterleitung gängiger Log- und Metrikdatenformate zu Logstash oder Elasticsearch.
- Logstash: Datenverarbeitungspipeline zum Erfassen, Filtern und Weiterleiten von Eventdaten an Elasticsearch oder andere Dienste.
- Elasticsearch: verteilte und horizontal skalierbare Such- und Analysemaschine zum Verwalten und Abfragen von Eventdaten.
- Kibana: Visualisierung von Eventdaten aus Elasticsearch und Konfiguration der Komponenten den Elastic Stacks.
Wie Elastic auf deren Website mittels erfolgreicher Anwendungsfälle aufzeigt, können einzelne Projekte oder die Kombination derer z.B. wie folgt genutzt werden:
Enterprise-Search: Mit dieser kann ein Unternehmen alle internen Daten durchsuchen, darunter Dokumente, E-Mails und andere Dateien. Im konkreten Fall hat ein Warenhaus die Funktion verwendet, um Rückgaben der Kunden zu validieren und somit Betrug zu verhindern, aber auch, um die Unternehmenswahrnehmung beim Kunden durch schnellen und kompetenten Kundenservice zu verbessern.
Observability: Jede Sekunde werden bei Walmart etwa 156 Bananen verkauft. Das Sammeln von Informationen wie diesen wird durch eine Self-Service-Analyseplattform für die Datenwissenschaftler seitens des Elastic Stacks ermöglicht. So können neben der Anzahl verkaufter Bananen pro Sekunde auch relevante Informationen zu den Verkaufszahlen aller Produkte und deren Kaufumstände aufbereitet werden. Dies ermöglicht Szenarien wie die automatische Lieferung, um beispielsweise eine Warenknappheit vorzubeugen.
Security: Das rechtzeitige Aufdecken von Finanzbetrug ist ein zeitkritisches Unterfangen. Durch die Verwendung des Elastic Stacks konnte der Zeitverzug von 24 Stunden auf wenige Minuten reduziert und somit Schäden abgewendet werden, bevor diese entstanden wären. Dies sparte einer Bank über 18 Monate ungefähr 35 Millionen Dollar.
Dies sind nur ein paar Anwendungsfälle des Elastic Stacks. Es wird jedoch deutlich, dass sich die Verwendung besonders in den drei genannten Bereichen für ein Unternehmen hinsichtlich BI und BA lohnen kann.
2. Inbetriebnahme
Innerhalb des Projekts wird der Elastic Stack durch Aufsetzen und Vernetzen mehrerer Docker-Container per Docker-Compose verwendet. Für Elasticsearch, Kibana und Logstash werden die Ports 9200, 5601 und 5044 konfiguriert.
user@host:~$ git clone https://github.com/deviantony/docker-elk.git
user@host:~/docker-elk$ docker-compose up3. Beats
Die Beats-Plattform bildet eine Lösung für die Erfassung und Verarbeitung gängiger Log- und Metrikdatenformate sowie deren Übermittlung an Logstash und Elasticsearch. Die als Beats oder Data-Shipper benannten Werkzeuge können direkt als Serveranwendung betrieben oder als Docker-Container aufgesetzt werden. Alle übertragenen Daten erfüllen das Elastic-Common-Schema (ECS), d.h. eine Open-Source-Spezifikation zur Normalisierung von Events mit dem Ziel, Eventdaten durch Metadaten zu ergänzen, um diese besser analysieren, vergleichen und visualisieren zu können. Dafür werden spezifische Felder sowie deren Datentypen definiert, z.B. der Zeitstempel eines Events (@timestamp), die IP-Adresse des Servers (server.ip) oder der Hash des Nutzers (user.hash), der mit einem bestimmten Event assoziiert wird.
Ausgehend vom Go-Framework libbeat besteht die Möglichkeit eigene Beats bzw. Data-Shipper zu entwickeln und auf spezifische Formate anzupassen. Für gängige Szenarien stehen vordefinierte Beats bereit, deren Eingabedaten im Folgenden aufgegriffen werden:
-
-
Metricbeat: Aufzeichnung von Host-System-Daten, wie z.B. der CPU-, Speicher- oder Netzwerkauslastung
-
Packetbeat: Fokus auf Netzwerkdatenverkehr und Monitoring von z.B. Latenzen oder Reaktionszeiten bei der Nutzung von HTTP
-
Winlogbeat: Analyse von Ereignisprotokollen unter Windows und Überwachung von bspw. Anmeldevorgängen oder Anschluss externer Geräte
-
Auditbeat: Monitoring von z.B. Prozessen und Nutzeraktivitäten auf Basis des Linux-Audit-Frameworks
-
Heartbeat: Überprüfung der Verfügbarkeit von Diensten (Pingen) inkl. Auswertung der Reaktionszeiten
-
Durch den Einsatz von Spooling, d.h. einer Verwahrung von Log- und Metrikdaten auf einem persistenten Speichermedium, kann eine Fortsetzung der Datenübermittlung nach z.B. einem Netzwerkausfall erreicht und somit der Verlust von Eventdaten minimiert werden. Außerdem sind Beats durch spezifische Überlastprotokolle in der Lage, die Lesegeschwindigkeit dynamisch anzupassen, falls etwa Logstash mehr Ressourcen für die Verarbeitung benötigt.
Beispiel
Die Kontrolle von Systemparametern wie der CPU-Auslastung spielt in Unternehmen hinsichtlich der Kosten- und Ressourcenkontrolle eine wichtige Rolle. Daher wird in diesem Beispiel das Auslesen dieser mit Hilfe von Metricbeat gezeigt. http://localhost:9200 und http://localhost:5601
user@host:~/docker-elk$ docker-compose upUm die Komplexität des Beispiels niedrig zu halten, wird Metricbeat direkt auf dem Host-System ausgeführt.
user@host:~$ curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-8.5.2-linux-x86_64.tar.gz
user@host:~$ tar xzvf metricbeat-8.5.2-linux-x86_64.tar.gzmetricbeat.yml
output.elasticsearch:
hosts: ["localhost:9200]
username: "elastic"
password: "changeme"reload.period“
user@host:~/metricbeat-8.5.2-linux-x86_64$ ./metricbeat setup --dashboards
user@host:~/metricbeat-8.5.2-linux-x86_64$ ./metricbeat -e -c metricbeat.yml -d "publish"In Kibana (http://localhost:5601) erfolgt nun das Anlegen einer Data-View unter „Stack Management/Data Views“. Das Index-Pattern wird auf „metricbeat-*“ festgelegt und „@timestamp“ als Timestamp-Field ausgewählt. Kibana erkennt den im vorangegangen Schritt erstellten Index automatisch. Die Eventdaten lassen sich unter Analytics/Discover tabellarisch und unter Analytics/Dashboards mit der Auswahl „[Metricbeat System] Host Overview ECS“ visuell anzeigen (siehe Abbildung 1).
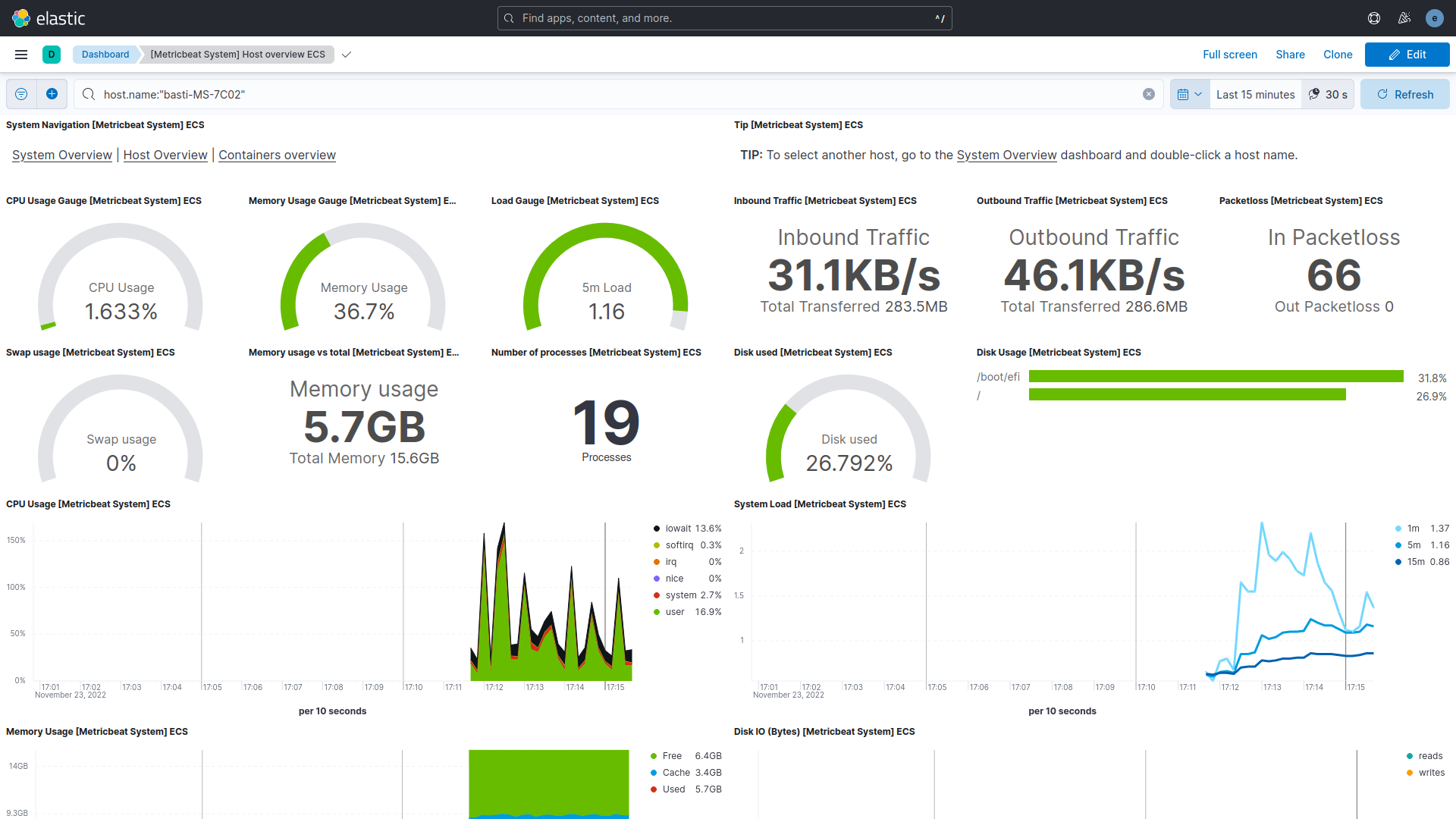
Abbildung 1: Kibana-Dashboard für Systemdaten
4. Logstash
Logstash bezeichnet eine Datenverarbeitungspipeline, die sich durch eine große Auswahl an Plugins für die Erfassung (Input), Analyse und Transformation (Filter) und Weiterleitung (Output) von Log-, Metric- und Anwendungsdaten auszeichnet. So können Eventdaten nicht nur zu Elasticsearch übertragen werden, sondern auch Gegenstand einer E-Mail darstellen oder als Eingabe für eine Redis-Datenbank dienen. Analog zu Beats besteht die Möglichkeit eigene Plugins für Logstash zu entwickeln, wobei Kenntnisse in der Programmiersprache Ruby notwendig sind. Unter „Stack Management/Pipelines“ in Kibana lassen sich eigene Datenverarbeitungsanweisungen realisieren, die mit Hilfe des „Pipeline-Viewers“ überwacht werden können. Eine Pipeline besteht aus mindestens einem Input, mindestens einem Output und kann optional um Filter ergänzt werden. Für den Output wird eine Dead-Letter-Queue betrieben, die eine Übermittlung ausstehender Eventdaten nach z.B. einem Netzwerkausfall sicherstellt.
Beispiel
RUN logstash-plugin install logstash-filter-jsonAnschließend wird die Konfigurationsdatei „logstash.conf“ (docker-elk/logstash/pipeline) angepasst, wobei die Einstellungen zum Bezug von Beats- und TCP-Daten und die Übermittlung an Elasticsearch bereits enthalten sind. Für den (periodischen) Abruf von API-Daten wird das Logstash-Plugin „HTTP-Poller“ als Input verwendet, welches die abzurufenden URLs sowie die Aufrufmethoden (z.B. get) zusammenfasst und den Abruftakt (30 Sekunden) spezifiziert. Über das JSON-Filter-Plugin werden die Rohdaten aus dem Feld „message“ in Schlüssel-Wert-Paare überführt. Zusätzlich wurde „stdout“ als Ausgabe ergänzt, um den korrekten Abruf auf der Konsole kontrollieren zu können. Für vereinfachtes Rechtemanagement werden in diesem Beispiel die Standard-Zugangsdaten für Elasticsearch verwendet, wovon in einer Produktionsumgebung abzusehen ist. Zuletzt wird für die API-Daten ein neuer Index „open-meteo-api“ angelegt, um diese von anderen Eventdaten abgrenzen zu können und um zukünftige Anfragen zu beschleunigen.
input {
beats { port => 5044 }
tcp { port => 50000 }
http_poller {
urls => {
http => {
method => get
url => "https://api.open-meteo.com/v1/forecast?latitude=51.34&longitude=12.37&hourly=temperature_2m"
}
}
schedule => { "every" => "30s" }
}
}
filter {
json { source => "message }
}
output {
elasticsearch {
hosts => "elasticsearch:9200"
index => "open-meteo-api"
user => "elastic"
password => "changeme"
}
stdout { }
}Durch Wechsel auf die „open-meteo-api*“-Data-View der Discover-Ansicht von Kibana, die analog zum Beispiel im Abschnitt Beats zunächst angelegt werden muss, können die erhaltenen und transformierten Daten schließlich eingesehen werden.
5. Elasticsearch
Nachdem durch Beats und Logstash Eventdaten aufgenommen und transformiert wurden, dient Elasticsearch als REST-basierte Such- und Analysemaschine der Indexierung, Speicherung und Abfrage dieser. Elasticsearch basiert auf der Suchmaschine Apache Lucene und arbeitet dokumentenorientiert, d.h. die Eventdaten müssen keinem festen Datenbankschema folgen, sondern definieren die Struktur, ähnlich zu JSON, in sich selbst. Für Abfragen, die über Elasticsearch-API-Endpunkte abgearbeitet werden, steht eine domänenspezifische Sprache (Query DSL) zur Verfügung. Durch den Betrieb auf potentiell mehreren Netzwerkknoten wird Elasticsearch auch als horizontal skalierbare, verteilte Suchmaschine bezeichnet, d.h. Anfragen werden an verschiedenen Knoten bearbeitet und die Ergebnisse zusammengeführt. Außerdem erfolgt standardmäßig eine Replikation der Eventdaten. Neben der Unterstützung von datums- und zeitbezogenen, numerischen und geographischen Datenformaten unterstützt Elasticsearch auch die Verwaltung von Text inkl. Volltextabfragen über invertierte Indizes. Durch das Ranking von Eventdaten wird erlaubt, die Reihenfolge der Ergebnisse einer Query zu modifizieren. Elasticsearch ist darüber hinaus in der Lage, Eingaben bei der Suche auf z.B. Rechtschreibfehler zu überprüfen und ggf. ein Fuzzy-Matching, d.h. das Einbeziehen von Eventdaten in die Ergebnismenge bei ausreichend hoher Ähnlichkeit, durchzuführen.
Beispiel
Einen Mehrwert aus den Daten der Wetter-API erhält man durch Speicherung und Indexierung, wodurch eine Durchsuchung bzw. Filterung erlaubt wird. Ausgehend vom vorherigen Abschnitt zu Logstash zeigt dieses Beispiel eine Möglichkeit der Datenabfrage. Folgender Curl-Befehl liefert die Eventdaten der letzten 30 Minuten und den Durchschnittswert der aufgenommenen Temperaturen im JSON-Format zurück. Für die HTTP-Basic-Authentifizierung werden Nutzername und Passwort hinzugefügt.
curl -XGET --user elastic:changeme "http://localhost:9200/open-meteo-api/_search" -H "kbn-xsrf: reporting" -H "Content-Type: application/json" -d'
{
"query": {
"range": {
"@timestamp": {
"time_zone": "+01:00",
"gte": "now-30m",
"lte": "now"
}
}
},
"aggs": {
"avg": {
"avg": {
"field": "hourly.temperature_2m"
}
}
}
}'Für die Aggregation gibt Elasticsearch beispielsweise folgendes Schlüssel-Wert-Paar zurück:
"aggregations":{
"avg": {
"value":2.3194444460705634
}
}6. Kibana
Obwohl Elasticsearch standardmäßig API-Endpunkte für den Abruf von Eventdaten im JSON-Format durch Curl oder Clients für spezifische Programmiersprachen bereitstellt, stellt die Visualisierung zumeist eine effizientere Form der Aufbereitung dar und ermöglicht einen tieferen Einblick sowie eine bessere Analysemöglichkeit. Kibana bietet eine freie Gestaltung von Dashboards und stellt eine Vielzahl von grafischen Komponenten zur Verfügung, u.a. Graphen, Histogramme, Linien-, Zeitreihen- und Kreisdiagramme sowie Karten für die Darstellung von Geodaten. Wie im Abschnitt Beats dargestellt wurde, stehen bereits nach dem Aufsetzen einige Dashboards zur Verfügung oder können über einen CLI-Befehl hinzugefügt werden. Für Eventdaten lassen sich Filter (Kibana Query Language, KQL) und Alarme definieren. Gekoppelt mit der eingebauten, unbeaufsichtigten Machine-Learning-Funktion lassen sich darüber beispielsweise Anomalien identifizieren und in Echtzeit Benachrichtigungen auslösen. Zum Teilen der Eventdaten stehen außerdem Exportfunktionen nach PDF, PNG, oder CSV zur Verfügung. Ebenso lassen sich Kibana-Boards in Webseiten einbetten. Neben der Visualisierung von Eventdaten ermöglicht Kibana einen Zugriff auf Funktionen des gesamten Elastic Stacks, z.B. lassen sich neue Datenquellen hinzufügen, Logstash-Pipelines definieren oder Elasticsearch-Queries über einen Editor erstellen und testen. Zur Begrenzung des Zugriffs kann auf das eingebaute Authentifizierungs- und Rollensystem zurückgegriffen werden.
Beispiel
Während sich die Abfrage von Eventdaten im JSON-Format über die Elasticsearch-API vor allem für die Nutzung in Drittsoftware anbietet, kann über die Nutzung von grafischen Komponenten in Kibana, die intern jene Abfragen nutzen, eine höhere Anschaulichkeit und ein besseres Verständnis über die erhaltenen Daten erreicht werden. Das Beispiel der Aggregation der Temperaturwerte aus dem Abschnitt zu Elasticsearch wird daher erweitert und auf ein Dashboard übertragen. Über „Dashboard/Create Dashboard“ lässt sich dieses erstellen und mit verschiedenen Komponenten befüllen. Standardmäßig kann im oberen, rechten Teil der Filterzeitraum bestimmt und die periodische Aktualisierung des Boards aktiviert werden. Im konkreten Fall werden die Eventdaten der letzten Stunde betrachtet und eine Aktualisierung aller 30 Sekunden festgelegt.
Für die Erstellung einer Komponente, die die Anzahl aller aufgenommenen Datensätze im Filterzeitraum zeigt, ist im Bearbeitungsmodus „Select Type/Aggregation Based/Metric“ und die „open-meteo-api*“-Data-View auszuwählen. Als Aggregationsmethode wird „Count“ übernommen und schließlich der Titel (Label) auf „Datensätze“ abgeändert.
Für die Darstellung der Temperaturwerte (siehe Abbildung 2) dient eine Komponente mit drei Manometern (Gauge), welche unter „Select Type/Aggregation Based/Gauge“ zu finden sind. Nach Auswahl der Data-View lassen sich Minimum (Min), Durchschnitt (Average) und Maximum (Max) als Metrik auswählen. Über „Options“ erfolgt schließlich die Bereichsanpassung und die Modifikation von Legende und Farben.
Zusätzlich wird ein weiterer Zeitfilter hinzugefügt, um die Suche innerhalb der gelieferten Eventdaten weiter verfeinern zu können. Grundsätzlich gibt es auch die Möglichkeit, den Filterzeitraum für einzelne Komponenten individuell anzupassen.
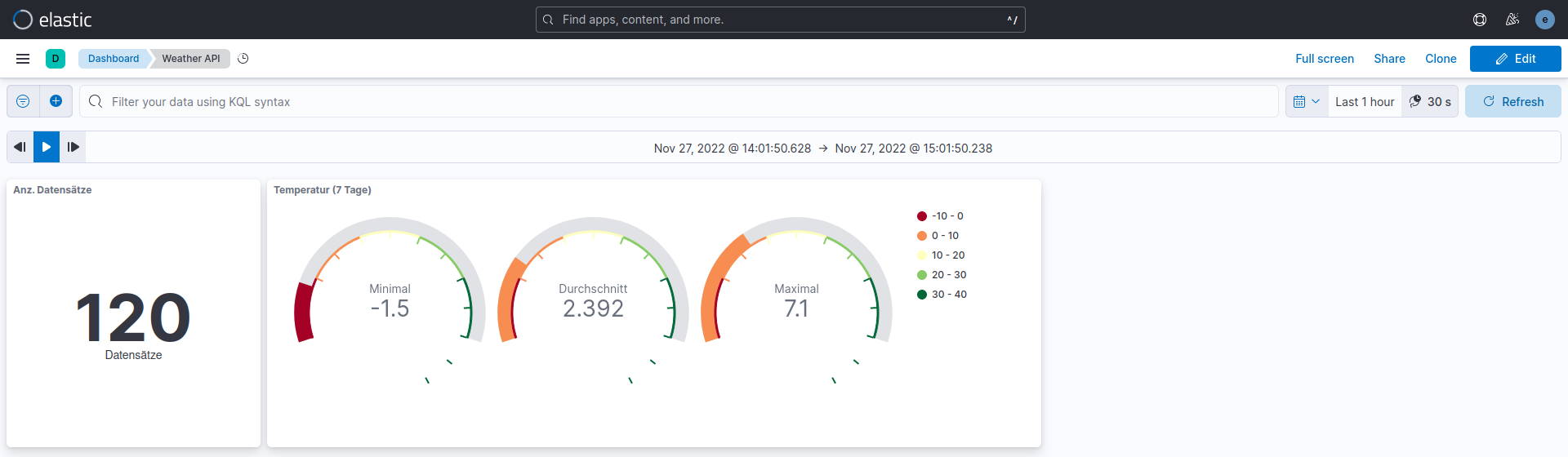
Abbildung 2: Kibana-Dashboard für Temperaturdaten
7. Prozessmodellierung
Zum Überblick über das vorangegangene Beispiel zur Verarbeitung und Visualisierung von Wetterdaten wird dieses als BPMN-Diagramm in Abbildung 3 aufbereitet. Der Fokus liegt insbesondere auf dem periodischen Abruf von API-Daten im JSON-Format, deren Verarbeitung und deren Darstellung mittels grafischer Komponenten in Kibana.

Abbildung 3: Verarbeitung und Visualisierung von Open-Meteo-Wetterdaten
8. Vorteile
Kostenlos & Open-Source: Ein Hauptgrund für die steigende Beliebtheit des Elastic Stacks ist die geringe finanzielle Barriere für den Einstieg. Alle Komponenten (Elasticsearch, Kibana, Logstash & Beats) sind kostenlos und Open-Source, bedeutet, es gibt keine Lizenzgebühren, was den Einstieg und die Verwendung in einer selbst gehosteten Umgebung begünstigt.
Verschiedene Hosting-Optionen: Für Unternehmen ist es sinnvoll aus verschiedenen Hosting-Optionen zu wählen. Je nach Ressourcen lässt sich eine selbstgehostete In-House-Variante umsetzen oder der Elastic Stack als dezentral verwalteter Dienst nutzen. Hierbei gibt es von Elasticsearch verschiedene Preismodelle für die Nutzung der Elastic-Cloud, alternativ auch andere externe Lösungen, wie z.B. Amazon OpenSearch.
Zentralisiertes Logging: Das im Elastic Stack integrierte zentrale Logging ermöglicht es, Logdaten von zunehmend komplexen Systemen auszuwerten und in einem einzigen Index zusammenzuführen. Dadurch können Zusammenhänge zwischen Daten verschiedener Quellen hergestellt werden und die Liste der Anwendungsszenarien um Dinge wie Ursachenanalyse und Monitoring erweitert werden.
Echtzeit-Datenanalyse & -Visualisierung: Kibana liefert die Möglichkeit, Echtzeitdaten aus Elasticsearch zu visualisieren und in individuell anpassbaren Dashboards darzustellen. Dadurch wird das Verständnis und eine schnelle Erkenntnis aus den Daten begünstigt und somit die Agilität des Unternehmens sowie Entscheidungsfindungen gefördert.
9. Nachteile
Komplexes Management: Der Elastic Stack fügt einem Projekt oder Unternehmen eine weitere Ebene der Komplexität hinzu. Die Einrichtung und Wartung des Systems muss somit mit dem Nutzen abgewägt werden, da dadurch zusätzliche Kosten entstehen. Elemente, die die Komplexität erhöhen, sind:
- Einrichten der Log-Analyse und Einspeisung
- Entwicklung von Daten-Pipelines
- Monitoring & Datensicherung
- Performance-Optimierung
- Testen & Konfigurieren
- Sicherheit, Fallback und Anwendungen der Daten
Wartungskosten: Um den Elastic Stack zu entwickeln, zu skalieren und zu erhalten werden Infrastruktur und Ressourcen benötigt. Die Kosten für Rechenleistung und Datenspeicherung hängen vom täglichen Logvolumen und dem Zeitraum der Archivierung ab. Diese Infrastrukturkosten tendieren mit der Zeit zu steigen, da sich in dynamischen Systemen Daten zunehmend anhäufen. Zusätzlich verursachen die Wartung und die Individualisierung des Systems bei Skalierung ebenfalls Kosten.
Stabilität: Bei wachsendem Datenumlauf im Elastic Stack kann es zu Problemen mit der Stabilität kommen. Wenn der Index die Limitation der Datenspeicherung des jeweiligen Knotens/Containers überschreitet, kann das Indexieren scheitern, was Datenverlust oder einen Absturz des System zur Folge haben kann.
10. Alternativen
Microsoft Power BI ist eine cloudbasierte Business-Intelligence-Plattform. Die Funktionalitäten sollen Unternehmen bei der Entwicklung von Berichten, Dashboards und Analysen unterstützen. Hierbei kann der Anwender Daten aus vielen verschiedenen Quellen verknüpfen und daraus unternehmensrelevante Einblicke gewinnen. Power BI nutzt hierfür die eigene Programmiersprache „M“ für die Erstellung von Abfragen. Analog zu Kibana können Daten in Echtzeit visualisiert und analysiert werden.
Salesforce Tableau ist ebenfalls ein cloudbasiertes Business-Intelligence-Tool, das es ermöglicht, Daten aus verschiedenen Quellen zu sammeln. Es bietet Benutzern die Möglichkeit, Daten in Echtzeit zu erfassen, zu analysieren und zu visualisieren. Mit Tableau können Benutzer Daten aus verschiedenen Quellen wie Excel, CSV, Salesforce, SQL-Server und mehr abrufen. Es bietet auch verschiedene Funktionen, mit denen Benutzer Daten in Dashboards, Berichte und andere interaktive Visualisierungen umwandeln können. Alle Komponenten sind über eine graphische Benutzeroberfläche zu erreichen.
11. Fazit & Ausblick
Datenmanagement spielt für technologiegetriebene Unternehmen eine zunehmend größere Rolle. Der Elastic Stack umfasst alle nötigen Werkzeuge zur Erfassung, Transformation und Aggregation von Eventdaten sowie deren Indexierung, Filterung und Visualisierung. Dies wurde innerhalb des Beitrags über den periodischen Abruf von Wetterdaten sowie deren Filterung per Curl-Befehl und Visualisierung mittels Kibana demonstriert. Ausgehend davon können weitere Eventdaten hinzugefügt und analysiert werden.
Besonders von Vorteil ist der Elastic Stack für Unternehmen, die mit Log- und Eventdaten skalieren. Durch den Open-Source-Charakter eignet es sich jedoch ebenso für den privaten Gebrauch. Die Möglichkeiten des Systems werden generell durch die Qualität der erfassten Daten limitiert. Im Optimalfall sollten die Eventdaten daher schon vorab in einem strukturierten Format, bspw. JSON, vorliegen oder ein Verfahren zum Parsen der Daten bekannt sein.
Abgesehen davon lässt sich der Elastic Stack nahezu endlos skalieren, sodass die Nutzung seitens des Unternehmens letztendlich vom Kosten-Nutzen-Faktor der jeweiligen Anwendung abhängt. Dieser kann je nach Bedarf in der Komplexität des Managements und den Wartungskosten stark variieren.
Im Endeffekt überwiegen die Vorteile gegenüber den Nachteilen. Wie in der Motivation angedeutet, findet der Elastic Stack zahlreiche Einsatzszenarien. Deshalb ist davon auszugehen, dass der Bedarf an solcher Tech-Stack-Software weiter anhalten wird. Besonders spannend könnten dabei neue Features, bspw. die sprachbasierte Suche, werden.
12. Referenzen
- https://www.elastic.co/de/elastic-stack/
- https://logz.io/learn/complete-guide-elk-stack/#intro
- https://www.informatik-aktuell.de/entwicklung/methoden/elastic-stack-mit-strukturierten-logs-schneller-fehler-finden.html
- https://www.elastic.co/de/beats/
- https://www.elastic.co/de/beats/filebeat
- https://www.elastic.co/de/beats/metricbeat
- https://www.elastic.co/de/beats/packetbeat
- https://www.elastic.co/de/beats/winlogbeat
- https://www.elastic.co/de/beats/auditbeat
- https://www.elastic.co/de/beats/heartbeat
- https://www.elastic.co/de/beats/functionbeat
- https://www.elastic.co/guide/en/ecs/current/ecs-reference.html
- https://logz.io/blog/elk-stack-on-docker/
- https://www.elastic.co/de/logstash/
- https://discuss.elastic.co/t/how-to-connect-to-an-api-using-logstash/192123/7
- https://www.capterra.com.de/compare/149304/176586/elasticsearch/vs/power-bi?vs[]=37660
- https://powerbi.microsoft.com/en-us/what-is-power-bi/
- https://www.elastic.co/de/elasticsearch/
- https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-fuzzy-query.html
- https://www.elastic.co/de/kibana/
- https://www.elastic.co/de/customers/
- https://www.tableau.com/de-de
- https://kruschecompany.com/de/elastic-stack-elk/#Fazit
- https://blog.ordix.de/elasticsearch-co