GlusterFS
Was ist Gluster FS
GlusterFS ist ein verteiltes, beliebig skalierbares Dateisystem, das Speicherelemente von mehreren Servern in einem einheitlichen Dateisystem zusammenfasst.
Webseite: https://www.gluster.org
Funktionsweise
- ein Server (Node) kann in physischer Form als Server oder Virtuelle Maschine eingebunden sein
- diese Server bilden einen Trusted Pool (Verbund vertrauenswürdiger Server)
- Speicher wird in Form von Bricks (Bausteinen) zur Verfügung gestellt
- auf denen Volumes (Laufwerke) gebildet werden
- ein PC kann sowohl Server als auch Client sein
Anwendungsmöglichkeiten
- Netzwerk-RAID analog zum Festplatten-RAID (Redundant Array of Independent Disks)
Zur Erinnerung werden die Geläufigsten im Nachfolgenden aufgelistet:
- RAID 0 (Striping)
Festplatten werden zu einem Volumen verbunden, die Lese-/Schreibzugriffe werden auf einzelne Speichermedien in Stripes verteilt. Daraus resultiert ein Geschwindigkeitszuwachs auf Kosten der Ausfallsicherheit.
- RAID 1 (Spiegelung)
Bei RAID1 werden Kopien der Daten auf redundante Datenträger geschrieben. Die Nutzbare Kapazität reduziert sich dadurch bei Verwendung von 2 Festplatten um die Hälfte. Dafür ist aber die Ausfallsicherheit durch das Vorhandensein der Spiegelung gegeben.
- RAID 5 (Striping + verteilte Parität)
Dieses RAID-Verbund benötigt mindestens 3 Laufwerke, wobei die Daten abwechselnd auf Festplatten verteilt werden. Dabei werden auf einem zufälligen Datenträger die Paritätsinformationen zur Rekonstruktion für den Fall eines Datenträgerausfalls gespeichert. Bietet bessere Leistung und höhere Sicherheit gegenüber einer Festplatte. Speicherkapazität wird um eine Festplatte reduziert.
- RAID 10 (Striping + Spiegelung)
Hier werden mindestens 4 Datenträger benötigt, welche dann verbunden werden, um die Vorteile des RAID 0 und RAID 1 zu kombinieren.
Betriebsmodi
- Distributed Storage (verteilt)
Ist dem RAID 0 ähnlich, allerdings werden die Files im Ganzen auf einzelne Bricks verteilt, beispielsweise nach Round Robin Prinzip
- Replicated Storage (gespiegelt)
Die Daten werden analog zu RAID 1 auf einzelne Bausteine redundant verteilt. Allerdings ist hier auch ungerade Anzahl an Bricks möglich, ähnlich wie bei RAID 1E
- Distributed Replicated Storage
Stellt die Kombination der beiden oben genannten Modi dar. Für die Verteilung ist der Translator verantwortlich. Es sind hier genauso Paare mit ungerader Anzahlen an Bricks möglich. Des Weiteren lässt sich hier die Geo-Replication einstellen.
- Dispersed Storage
hat Ähnlichkeit zu dem RAID 5, allerdings werden Fragmente statt Paritätsinformationen zur Rekonstruktion auf alle Bricks verteilt (Erasure Coding). Beim Einstellen der 4+2 Konfiguration, können bis zu 2 Bricks/Nodes ausfallen.
- Distributed Dispersed Storage
Hier werden die Daten durch den Translator auf mehrere Dispersed Volumen nacheinander verteilt.
Vor- und Nachteile
Vorteile:
- Gute Auslastung vorhandener Kapazitäten
- Erhöhung der Ausfallsicherheit
- Verteilung der Netzlast
- Sehr gute Skalierbarkeit
Nachteile:
- Schaffung einer komplexeren Netzwerkstruktur
- Erhöhter administrativer Aufwand bei der Einrichtung
- Schnelle Netzwerkinfrastruktur nötig
- Zusätzlicher Aufwand zur technischen Absicherung
Alternativen
- Ceph
- BeeGFS
Demo-System
Host: Dell Workstation Precision T7910

- 2x Intel E5-2640 v3 (8 Cores / 16 Threads)
- 64 GB DDR4-RAM
- 120 GB SSD

VM’s:
 21.04
21.04- 11 Nodes
- 1 vCores
- 4096 MB RAM
- 10 GB Space
- Windows 10
- 1 Node
- 4 vCores
- 4096 MB RAM
- 10 GB Space
Zusätzlich benötigte Software Pakete (Ubuntu):
- glusterfs-server
- samba
Konfiguration:
- IP-Adressen
- hosts Datei
- Trusted Storage Pool (TSP)
- glusterFS Volumes
Detaillierte Node Konfiguration
IP-Adressen wurden wie folgt festgelegt.
- node-01: 192.168.1.1
- node-02: 192.168.1.2
- …
- node-14: 192.168.1.14
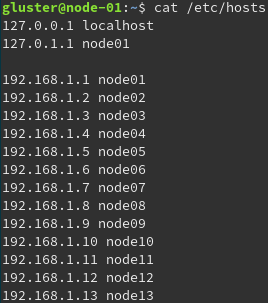
Bei allen Nodes (Ubuntu) die dem TSP beitreten sollen, wurden die Hosts mit ihren dazugehörigen IP-Adressen in der hosts Datei eingetragen.
Beispiel node-01
Erstellen der TSP
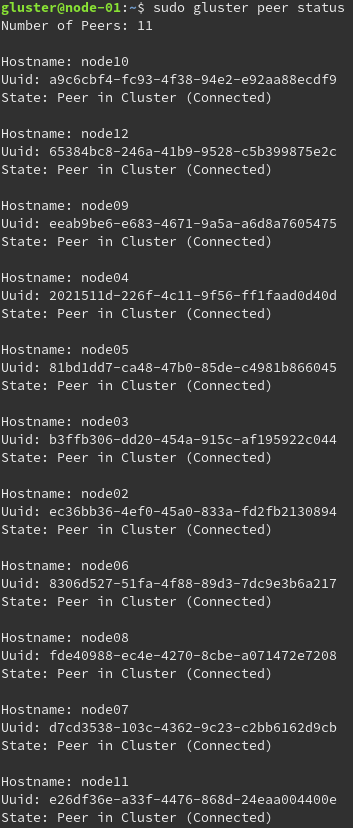
Um einen Node dem TSP hinzuzufügen muss der Befehl “sudo gluster peer probe node(Nummer)“ für jeden Node ausgeführt werden.
Zur Überprüfung der Konnektivität der Nodes wird “sudo gluster peer status“ ausgeführt.
Erstellen der Volumes
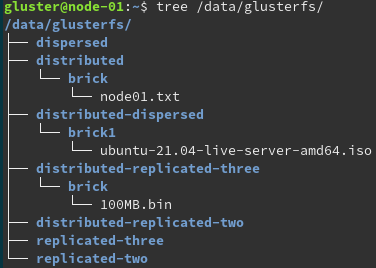
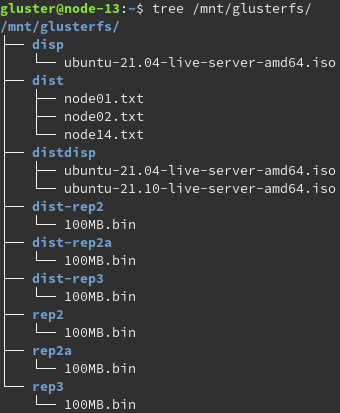
Bevor die Volumes erstellt werden können muss noch die Ordnungsstruktur erzeugt werden. Dies wurde durch eines selbst erstellten Batch Skript realisiert. Folgende Ordnerstruktur ist dabei entsanden.
Danach können die Volumes erstellt und gestartet werden werden.
sudo gluster volume create dist node0{1..2}:/data/glusterfs/distributed/brick
sudo gluster volume start dist
sudo gluster volume create rep2 replica 2 transport tcp node0{3..4}:/data/glusterfs/replicated-two/brick
sudo gluster volume start rep2
sudo gluster volume create rep2a replica 2 arbiter 1 transport tcp node0{3..5}:/data/glusterfs/replicated-two/bricka
sudo gluster volume start rep2a
sudo gluster volume create rep3 replica 3 transport tcp node0{5..7}:/data/glusterfs/replicated-three/brick
sudo gluster volume start rep3
sudo gluster volume create dist-rep2 replica 2 transport tcp node0{8..9}:/data/glusterfs/distributed-replicated-two/brick node1{0..1}:/data/glusterfs/distributed-replicated-two/brick
sudo gluster volume start dist-rep2
sudo gluster volume create dist-rep2a replica 2 arbiter 1 transport tcp node0{7..9}:/data/glusterfs/distributed-replicated-two/bricka node1{0..2}:/data/glusterfs/distributed-replicated-two/bricka
sudo gluster volume start dist-rep2a
sudo gluster volume create dist-rep3 replica 3 transport tcp node0{1..6}:/data/glusterfs/distributed-replicated-three/brick
sudo gluster volume start dist-rep3
sudo gluster volume create disp disperse-data 4 redundancy 2 transport tcp node0{7..9}:/data/glusterfs/dispersed/brick node1{0..12}:/data/glusterfs/dispersed/brick
sudo gluster volume start disp
sudo gluster volume create distdisp disperse-data 4 redundancy 2 transport tcp node01:/data/glusterfs/distributed-dispersed/brick1 node02:/data/glusterfs/distributed-dispersed/brick2 node03:/data/glusterfs/distributed-dispersed/brick3 node04:/data/glusterfs/distributed-dispersed/brick4 node05:/data/glusterfs/distributed-dispersed/brick5 node06:/data/glusterfs/distributed-dispersed/brick6 node07:/data/glusterfs/distributed-dispersed/brick7 node08:/data/glusterfs/distributed-dispersed/brick8 node09:/data/glusterfs/distributed-dispersed/brick9 node10:/data/glusterfs/distributed-dispersed/brick10 node11:/data/glusterfs/distributed-dispersed/brick11 node12:/data/glusterfs/distributed-dispersed/brick12
sudo gluster volume start distdisp
Bei den Varianten mit zwei replica kann es zu so genannten “split-brain“ Problem kommen. Problemlösung ist die Verwendung von replica 3 oder die Nutzung von Arbiter. Siehe dazu: https://docs.gluster.org/en/latest/Administrator-Guide/Split-brain-and-ways-to-deal-with-it/ Zusätzlich kann auch ein Server-seitiges “Quorum“ für die Volumes festgelegt werden, welches Prozentual angibt wie viele Bricks online sein müssen um das Volume schreibbar bereit zu stellen. Dies verhindert inkonsistente Datenstände.
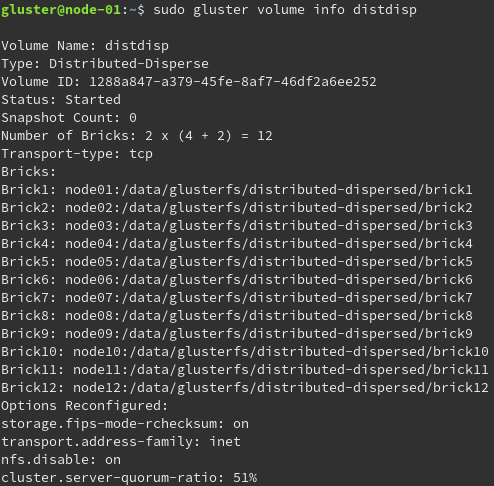
Beispielhafte Überprüfung eines Volumes.
Einbinden und Bereitstellen der Volumes
Node-13 wurde dazu genutzt alle Volumes Lokal einzubinden und durch einen Samba Share für Windows Clients bereit zu stellen.
sudo mount -t glusterfs node01:dist /mnt/glusterfs/dist
sudo mount -t glusterfs node01:rep2 /mnt/glusterfs/rep2
sudo mount -t glusterfs node01:rep2a /mnt/glusterfs/rep2a
sudo mount -t glusterfs node01:rep3 /mnt/glusterfs/rep3
sudo mount -t glusterfs node01:dist-rep2 /mnt/glusterfs/dist-rep2
sudo mount -t glusterfs node01:dist-rep2a /mnt/glusterfs/dist-rep2a
sudo mount -t glusterfs node01:dist-rep3 /mnt/glusterfs/dist-rep3
sudo mount -t glusterfs node01:disp /mnt/glusterfs/disp
sudo mount -t glusterfs node01:distdisp /mnt/glusterfs/distdisp
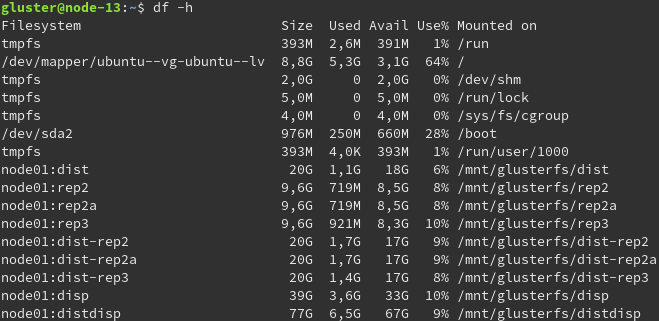
Ausgabe der Mountpunkte und Verzeichnisstruktur mit enthaltenen Dateien.
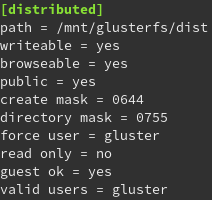
Es erfolgt nun die Konfiguration der Samba Shares in der Datei “/etc/samba/smb.conf“
Beispielhafte Ausgabe:
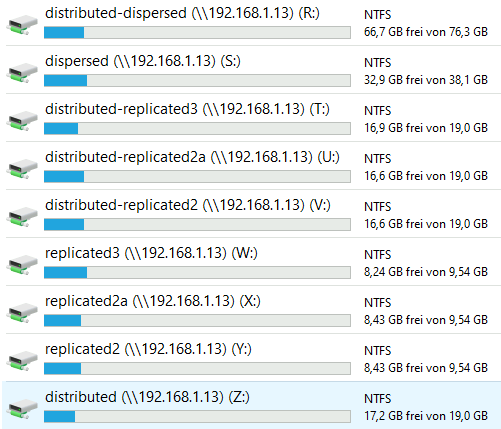
Damit ist das Einbinden der Samba Shares in Windows möglich.
Fazit
Nach einer Kurzen Einlesephase in das GlusterFS Universum ist die Bedienung und Wartung des TSP und der Volumes keine Herausforderung mehr.
Das System ist leicht zu bedienen, es kann sehr gut Skaliert werden. Die Ausfallsicherheit kann beliebig erhöht werden. Die Netzwerklast wird besser Verteilt, welche auch ein Geschwindigkeitsvorteil mit sich bringt.
Grenzen der Volumengröße wird durch das verwendete Dateisystem vorgegeben. Zum Beispiel ist bei ext4 die Obere Grenze 1 EiB welches 1024 PB entspricht, oder auch ZFS mit einer oberen Grenze von 16 EiB.
Unterstützung von GlusterFS auf Breiter Ebene, so ist die Verwendung von Windows, Linux und Mac als Endbenutzer Client möglich. (MacOS nicht getestet, aber gelesen)
Zu beachten ist das dabei eine komplexe Netzwerkstruktur geschaffen wird die einen erhöhten administrativen Aufwand schafft.
Quellen
https://docs.gluster.org/en/latest/Administrator-Guide/
https://glusterdocs.readthedocs.io/en/latest/Administrator%20Guide/Setting%20Up%20Clients/
Eine Antwort auf “GlusterFS”