Damit Prozesse in Betrieben am Laufen gehalten werden können, ist es nötig, diese zu überwachen. Dies gilt für die Prozesse in der Produktion bis hin zu denen der Geschäftsführungsebene. Verkaufszahlen sollten möglichst aktuell sein, um die richtigen Entscheidungen für den Betrieb treffen zu können. Und wenn Fehler in der Produktionskette auftreten, sollen diese schnell erkannt, identifiziert und lokalisiert werden.
Grafana ist eine kostenlose Open-Source-Monitoring-Software, die bei diesen Aufgaben unterstützen soll. Es können dabei Prozesse für die unterschiedlichen Ebenen eines Betriebs überwacht werden. Dazu werden auf Dashboards verschiedene, zusammengehörende Daten von verschiedenen Datenquellen auf einer Seite zusammengestellt. Abhängig von der Struktur der Daten können innerhalb eines Dashboards verschiedene Grafiken genutzt werden, um die zu überwachenden Informationen anzuzeigen. Dabei stellt Grafana standardmäßig verschiedene Datenquell-Integrationen und Panel-Typen (Grafana-Bezeichnung für eine Grafik) zur Verfügung.Im Umfang enthalten sind dabei Plotter, Diagramme, Heatmaps, etc. Darüber hinaus können mit Plug-ins weitere Drittanbieter ihre Integrationen und Panels ergänzen. Dazu zählen die gängigen DBMS, Google-Dienste, GitHub, GitLab, etc. Einige Plug-Ins sind jedoch nur in der SaaS-Version verfügbar. Diese ist ab einem gewissen Ressourcenverbrauch jedoch zahlungspflichtig, sodass je nach Anwendungsfall für einige Plug-Ins gezahlt werden muss. Ein üblicher Anwendungsfall ist, die Tabellen einer Datenbank auszulesen und mithilfe von SQL-Queries die Informationen zu extrahieren, die visualisiert werden sollen. Auf der Webseite von Grafana wird der Nutzen wie folgt beschrieben:
“Query, visualize, alert on, and understand your data no matter where it’s stored. With Grafana you can create, explore, and share all of your data through beautiful, flexible dashboards.” (GrafanaLabs)
Zur Überwachung zählt dabei nicht nur die Visualisierung der Daten, sondern auch, dass sich das System meldet, falls Prozesse sich außerhalb festgelegter Parameter befinden. Dazu können innerhalb der Panels Grenzwerte festgelegt werden, die zu einem Alerting führen, sobald diese überschritten werden.
Im folgenden Blogbeitrag soll die Software Grafana im Kontext eines Betriebes, dass Produkte verkauft, mithilfe von Beispielen demonstriert werden.
Zeitreihendatenbanken
Als Datenquelle werden in Grafana u. a. Zeitreihendatenbanken (Time Series Database, TSDB) eingesetzt. TSDB sind spezielle NoSQL-Datenbanken, d. h. Datenbanken mit nichtrelationaler Datenspeicherung, mit Fokus auf Zeitreihen mit einem Zeitstempel pro eingefügtem Wert. Auch erweiterte relationale Datenbanksysteme werden eingesetzt. Zusätzlich können Tags und weitere Werte an den Datensatz angehängt werden, die z. B. der Identifikation der Datenquelle dienen können. Gruppierung der Daten findet demzufolge über den existierenden Tags oder nach Zeitbereichen (pro Tag, Monat, Jahr, …) statt.
Ein Problem bei der Arbeit mit Zeitreihen ist der Umgang mit großen Datensätzen, wie sie u. a. beim Logging mehrerer Sensoren auftreten können. Denkbar ist die Verwendung von zusätzlichem Load Balancing zwischen mehreren Datenbanken. Dies ist nicht unter Verwendung gleicher Konsistenz- und Latenzanforderungen möglich. Gelöst wurde dieses Problem unter anderem durch den Einsatz von NoSQL-Datenbanken. Mögliche formulierte Einschränkungen auf RDBMS sind Insertoperationen über gruppierten Daten, und Einschränkungen der nachträglichen Veränderung von Daten und der möglichen Abfragen. Diese können sich auf einfache Aggregationen, wie Durchschnitts- oder Maximalwerte beschränken.
Eine besondere Metrik zur Einordnung von TSDB kann die Granularität sein, die den minimalen zeitlichen Abstand zwischen zwei Werten angibt, wobei diese durch Timestamps bei einer Millisekunde liegen kann. Bei der Abfrage ist die Granularität unter Umständen kleiner als bei der Speicherung. Ausgewertet nach Google Suchergebnissen sehen Bader, Kopp und Falkenthal (2017) als wichtigste Vertreter der reinen TSDB-Systeme auch Elasticsearch, Prometheus und InfluxDB (mit absteigender Rangfolge), welche auch bei Grafana eingesetzt werden.
Aufbau
Die Oberfläche von Grafana umfasst Einstellungen zum Hinzufügen von Datenquellen (Data Source in Grafana), Visualisierungswerkzeuge zur graphischen Aufbereitung von Daten (Dashboards und Panels), sowie Bearbeitungsseiten zur Abfrage und Operation auf den Daten (Query und Transform).
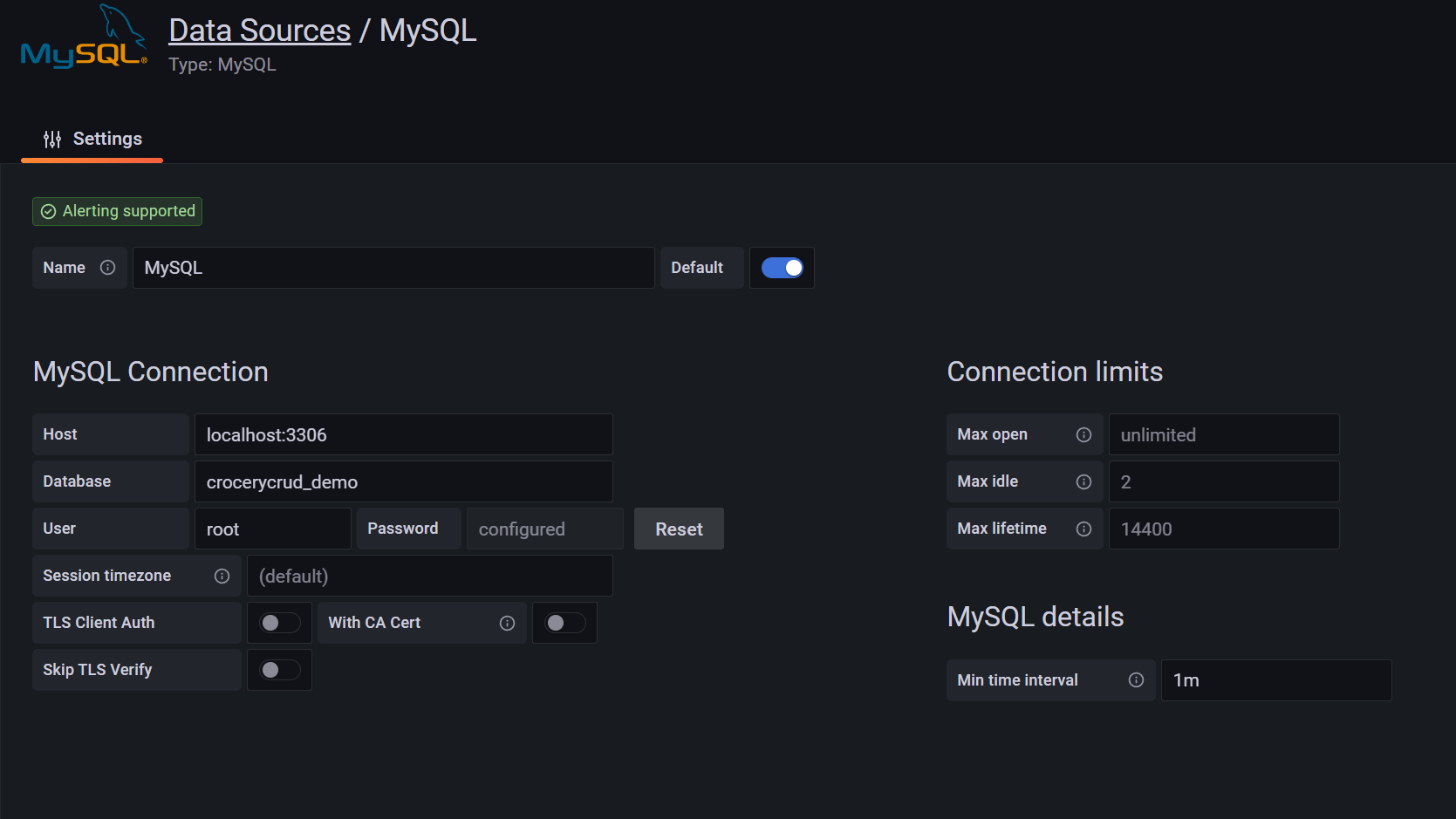
Data Source
Quelle: eigene Darstellung
Grafana bietet durch Data Sources die Möglichkeit, Daten von verschiedenen Quellen zu beziehen. Diese Daten sind meist in tabellarischer Form. Aus den Tabellen können dann Grafiken generiert werden. Für viele gängige Systeme wie z.B. MySQL, Jira, GitHub oder auch Azure werden Plugins angeboten, mit Hilfe deren APIs gewünschte Daten abgerufen werden können. Je nach verwendeter Quelle werden Zugangsdaten mit den entsprechenden Berechtigungen benötigt, damit die Daten abgerufen werden können. Es können beliebig viele Datenquellen eingerichtet werden. Wenn keine Plugins für die benötigte API existieren, können diese, mithilfe der von Grafana zur Verfügung gestellten Schnittstellen, selbst implementiert werden.
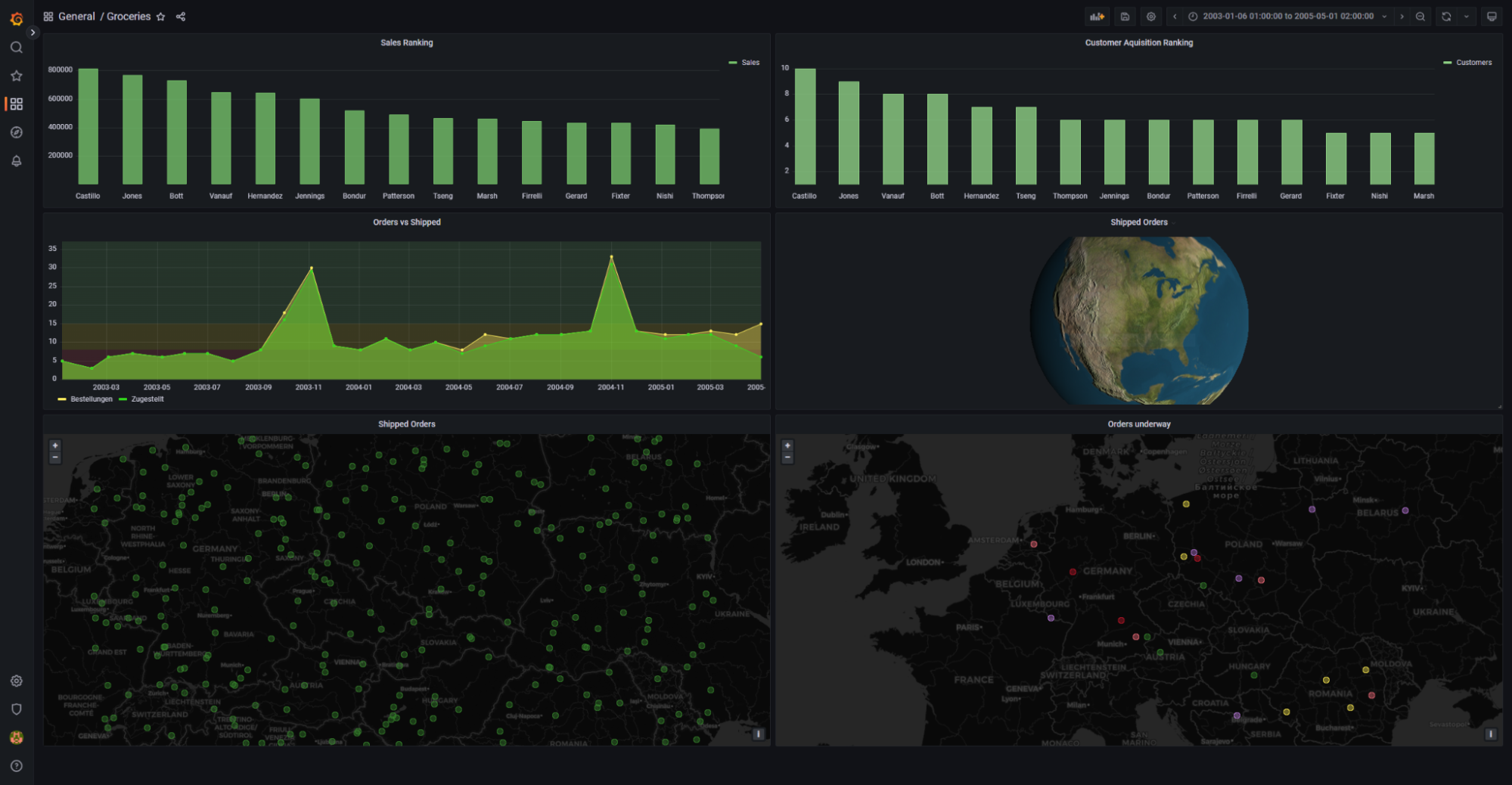
Dashboards und Panels
Quelle: eigene Darstellung
Ein Dashboard ist dazu da, dem User eine Übersicht über ein gewisses Themengebiet zu verschaffen, in dem relevante Daten auf eine anschauliche Art und Weise visualisiert werden. Ein Dashboard besteht dabei aus mehreren Panels, die sich in ihrer Anordnung, Größe und vor allem Inhalt komplett individuell einstellen lassen. So lassen sich beliebig viele Dashboards mit beliebig vielen Panels füllen. Die Dashboards lassen sich in Ordnern organisieren. Die Panels bieten sehr viele verschiedene Arten der Datendarstellung. Es gibt gängige Darstellungen wie Balkendiagramme oder XY Plots, aber auch spezifische Möglichkeiten für Visualisierungen wie zum Beispiel GeoMaps für GPS-Koordinaten oder Heatmaps. Falls die Standardlösungen nicht ausreichen, gibt es auch hier die Möglichkeit Plugins zu verwenden oder eigene Lösungen zu implementieren.
Query und Transform
Quelle: eigene Darstellung
Möchte man mit Grafana Daten von einem System Daten abrufen, um diese zu visualisieren, wird eine Query verwendet. Eine Query im Bezug zu Grafana Data Sources ist eine Abfrage an ein System, welches definiert, was für Daten benötigt werden. Diese Daten werden dann vom angefragten System an Grafna geschickt und sofern sie das noch nicht sind, in tabellarische Form umgewandelt. Die Tabellen, welche durch die Data Sources geliefert werden, können je nach Quelle mit Querys dem Anwendungsfall angepasst werden. Für verschiedene Datenbanken-Quellen gibt es zum Beispiel die Möglichkeit, Querys zu definieren oder mit einer grafischen Oberfläche zusammenzustellen.
Sind die Daten, wie sie aus der Data Source kommen nicht in dem gewünschten Format, bieten Transforms die Möglichkeit, auf den in Tabellen vorliegenden Daten Transformationen vorzunehmen, bevor diese in der Grafik angezeigt werden. Diese Transformationen können einfache arithmetische (und andere) Operationen sein, wie zum Beispiel. dem Umbenennen einer Spalte bis hin zu komplexen Ausdrücken, um die Aussage einer Tabelle zu ändern.
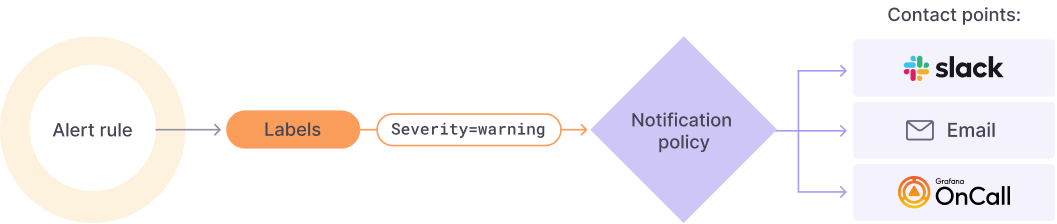
Neben der Möglichkeit einer passiven Überwachung bietet Grafana einen Alerting-Mechanismus an, der eine automatische Überprüfung der Schwellenwerte von Metriken mit der Auslösung von Aktionen verknüpft. Da die Daten in Grafana in einer tabellenartigen Form vorliegen, können Bedingungen über mehrere Werte geschrieben werden. Dadurch ist es möglich mehrere Alarme gleichzeitig auszulösen, dies nennt Grafana „Multi-Dimensional Alerting“.
Zum Auslösen eines Alarms müssen folgende Einstellungen konfiguriert sein:
Aktivieren eines Benachrichtigungsziels: Durch Anbindung an E-Mail- und Chat-Server kann das System ausgehende Meldungen verschicken. Nach Einbindung muss eine Regel aufgestellt werden, die das genaue Ziel (z. B. eine E-Mail-Adresse) und die Periodizität der Benachrichtigungen angibt.
Festlegen von Parametern: Damit ein Alarm auslöst, muss dieser konfiguriert werden. Hierzu benötigt es mindestens eine Anfrage auf einer Datenquelle, die analog zu einem Panel aufgebaut ist. Hinzu kommt eine Bedingung, die z. B. auf die Überschreitung eines Schwellenwertes überprüft, die Anzahl und Geschwindigkeit der Abfragen und die Verzögerung des Auslösens ähnlich einer Hysterese
Verknüpfen von Auslöser und Empfänger: Durch Festlegen von Schweregraden und Kategorisierung der Meldung kann der Alarm den richtigen Zielen zugeordnet werden
Sind kurzfristig keine Alarme erwünscht, besteht die Möglichkeit, Alarme zu pausieren beziehungsweise stummzuschalten. Dabei können wiederkehrende Zeiträume festgelegt werden. Sind die inkludierten Funktionen von Grafana für den gewählten Anwendungsfall nicht ausreichend, können externe Tools zur Benachrichtigungsverwaltung eingesetzt werden, wie beispielsweise Prometheus.
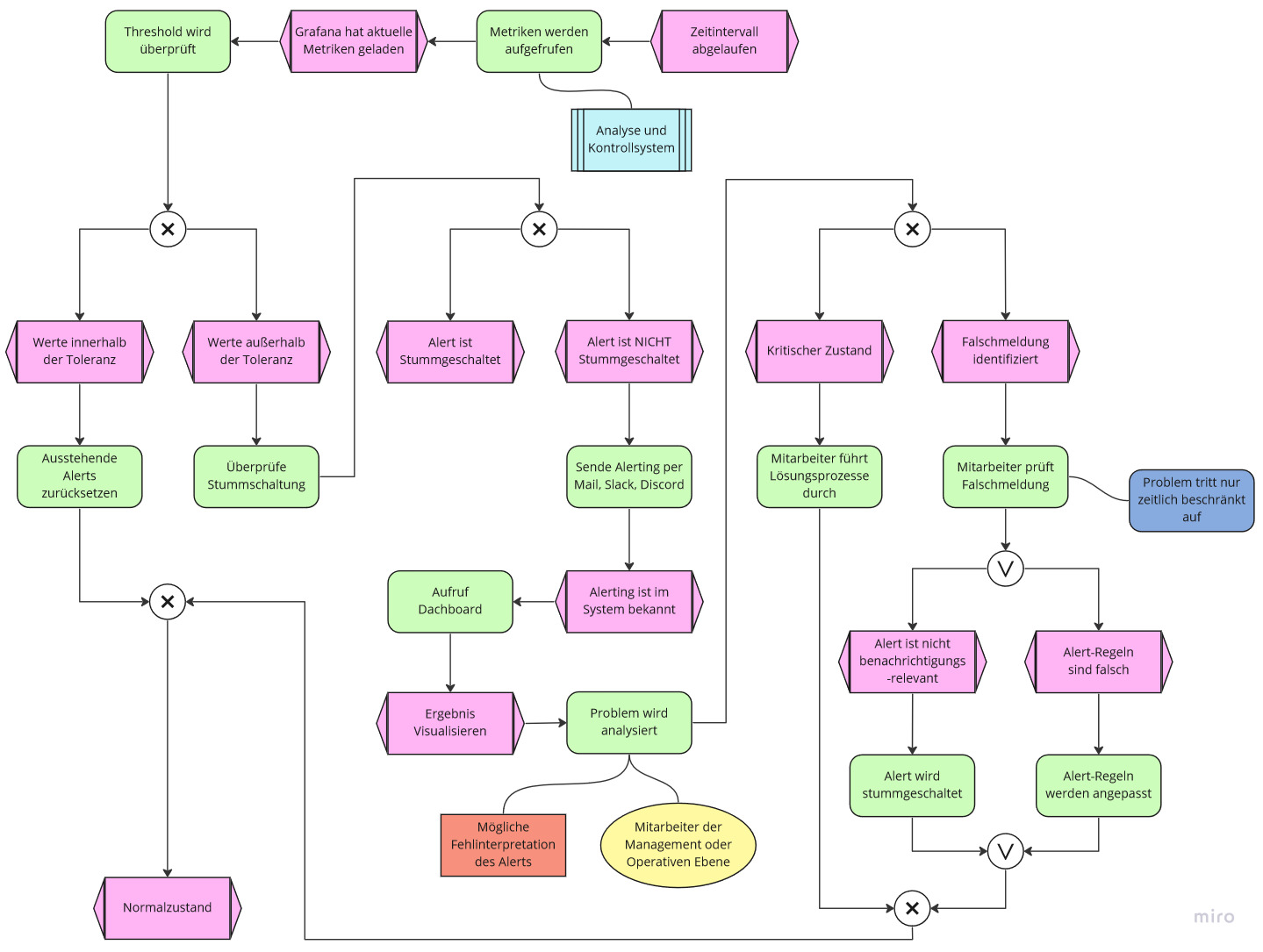
Im Kontext eines Betriebes, dass das Alerting-System von Grafana verwenden möchte, könnte ein Prozess wie nachfolgend im EPK definiert sein. Grafana ruft in vorher festgelegten Abständen die Daten der Data-Sources ab. Auf Basis dessen kann dann entschieden werden, ob sich die relevanten Metriken innerhalb festgelegter Grenzwerte befinden. Für den Fall, dass sich die Werte innerhalb der Toleranz befinden, werden die ausstehenden Alerts zurückgesetzt und das System befindet sich im Normalzustand. Andernfalls wird zunächst überprüft, ob der Alert stummgeschaltet ist. In diesem Fall passiert nichts. Ansonsten wird über den vorher festgelegten Benachrichtigungsweg (zum Beispiel per Mail) dem Betrieb mitgeteilt, dass Handlungsbedarf besteht. Ein Mitarbeiter kann nun auf die Meldung reagieren. Dazu ruft dieser Grafana auf, welche die Metrik visualisiert. Nun ist es Aufgabe des Mitarbeiters, das Problem zu lokalisieren und zu bewerten. Falls es sich um einen falschen Alarm handelt, muss entweder die Alerting-Regel angepasst werden (zum Beispiel Grenzwerte erhöhen) oder der Alert ganz stummgeschaltet werden. Falls jedoch ein kritischer Zustand entdeckt wird, müssen weitere Lösungsprozesse angestoßen und durchgeführt werden, bis das System schlussendlich wieder in einem Normalzustand ist.
EPK – Quelle: eigene Darstellung)
Alternativen
Mit Kibana ist es ebenfalls möglich, Dashboards zu bauen, in denen Daten visualisiert werden können. Anders als Grafana, wird hier der Fokus jedoch auf die Auswertung von Logging-Nachrichten gelegt. So ist hier Full-Text-Data-Querying möglich, was bei Grafana nicht möglich ist. Jedoch ist die einzige Datenquelle für Kibana die ElasticSearch. Hier bietet Grafana eine größere Bandbreite an Datenquellen und eignet sich damit eher für die Visualisierung von verschiedenen Metriken innerhalb des eigenen Systems.
Abgesehen von Kibana gibt es viele weitere Anwendungen und Dienste wie Splunk, Datadog, etc. Diese unterscheiden sich zu Grafana mit zusätzlichen Analysetools, besonders im Bereich der Analyse von Logging-Daten. Grafana ist im Vergleich ein breiter aufgestelltes Tool, das die unterschiedlichsten Daten visualisieren kann, ohne sich dabei auf spezielle Daten zu fokussieren. Dafür bietet es die größte frei zugängliche Sammlung von Visualisierungen beziehungsweise Diagrammtypen.
Installation
Grafana kann unter Linux, Mac und Windows installiert werden, es gibt aber auch Docker-Container und verschiedene ARM-Versionen für Linux. Zum Betrieb von Grafana ist grundsätzlich keine Einrichtung einer separaten Datenbank nötig, da die Installation einen SQLite Server umfasst. Soll trotzdem eine andere Datenbank verwendet werden, muss das beim Einrichten spezifiziert werden. Offiziell unterstützt werden SQLite, MySQL oder PostgreSQL. Bei einer selbst gehosteten Version von Grafana ist der Name und das zugehörige Passwort des Admin-Accounts „admin“. Diese Einstellungen lassen sich in der Konfiguration ändern oder deaktivieren.
Wird ein Cloud-Dienst verwendet und Plugins sollen installiert werden, können diese über das Web-Interface verwaltet werden. Bei einem selbständig gehosteten Server kann das Grafana-CLI unter „Grafana\bin\“ verwendet werden. Dazu wird folgender Befehl verwendet um das Plugin zu installieren:
grafana-cli plugins install plugin-bezeichner
Soll ein Paket verwendet werden, welches nicht über Grafana bezogen werden kann, dann wird es direkt unter „Grafana\plugins\“ abgelegt. Dieser Ort lässt sich auch in der Konfiguration ändern. Nachdem das Paket abgelegt oder erfolgreich installiert wurde, ist ein Neustart des Servers notwendig, damit die Änderungen erkannt werden.
Fazit
Im vorangegangenen Blogbeitrag wurde erläutert, wie mit Grafana unterschiedlichste Datenquellen visualisiert und überwacht werden können. Dazu steht eine breite Menge von Panel-Typen zur Verfügung. Mit Alertings können zudem Prozesse, die außerhalb festgelegter Systemparameter liegen, identifiziert werden. Für private Anwendungen oder einfache bis fortgeschrittene Überwachung von Prozessen eignet sich Grafana gut, auch deshalb, weil die Anwendung durch ihren Open-Source Ansatz für jeden zugänglich ist. Es ist nicht notwendig, ein eigenes Monitoring-System für seinen Betrieb zu entwickeln, sondern muss nur angeben, welche Daten wie angezeigt werden sollen. Für große Betriebe, die jedoch tiefergehende Analysen ihrer Daten benötigen, wie zum Beispiel von Logging-Daten, sind andere Anwendungen vorzuziehen.