
Obsidian
Was ist Obsidian?
Obsidian ist ein Werkzeug zur Erstellung von Wissensdatenbanken auf Basis simpler Textdateien. Die Applikation ermöglicht Text, aber auch eine Vielzahl an Formaten von Mediendateien zu organisieren, anzuzeigen und untereinander zu verlinken. Die Kernfunktion von Obsidian ist es, diese Dateien übersichtlich als Wissensgraph darzustellen. Dadurch ergibt sich eine Vielzahl an Anwendungsgebieten, von der Organisation von persönlichen Dateien bis hin zur Planungsunterstützung für größere Projekte.
Obsidians Funktionsumfang kann außerdem durch Plugins erweitert werden. Neben hunderten von wählbaren, bereits vorhandenen Erweiterungen besteht außerdem auch die Möglichkeit eigene Plugins zu erstellen. Die Entwickler stellen sogar Tutorials und Beispielplugins zur Verfügung, da eine der Hauptphilosophien von Obsidian ist, dass es einfach Erweiterbar ist und Funktionen in der Applikation selbst integriert werden können.
Die beschreibenden Textdateien sind in der Auszeichnungssprache Markdown, von welcher auch beinahe der volle Funktionsumfang in Obsidian genutzt werden kann.
Somit ist Obsidian im einfachsten Fall ein Notizblock, aber im Allgemeinen eher das, was man daraus macht.
Interface und Funktionsweise
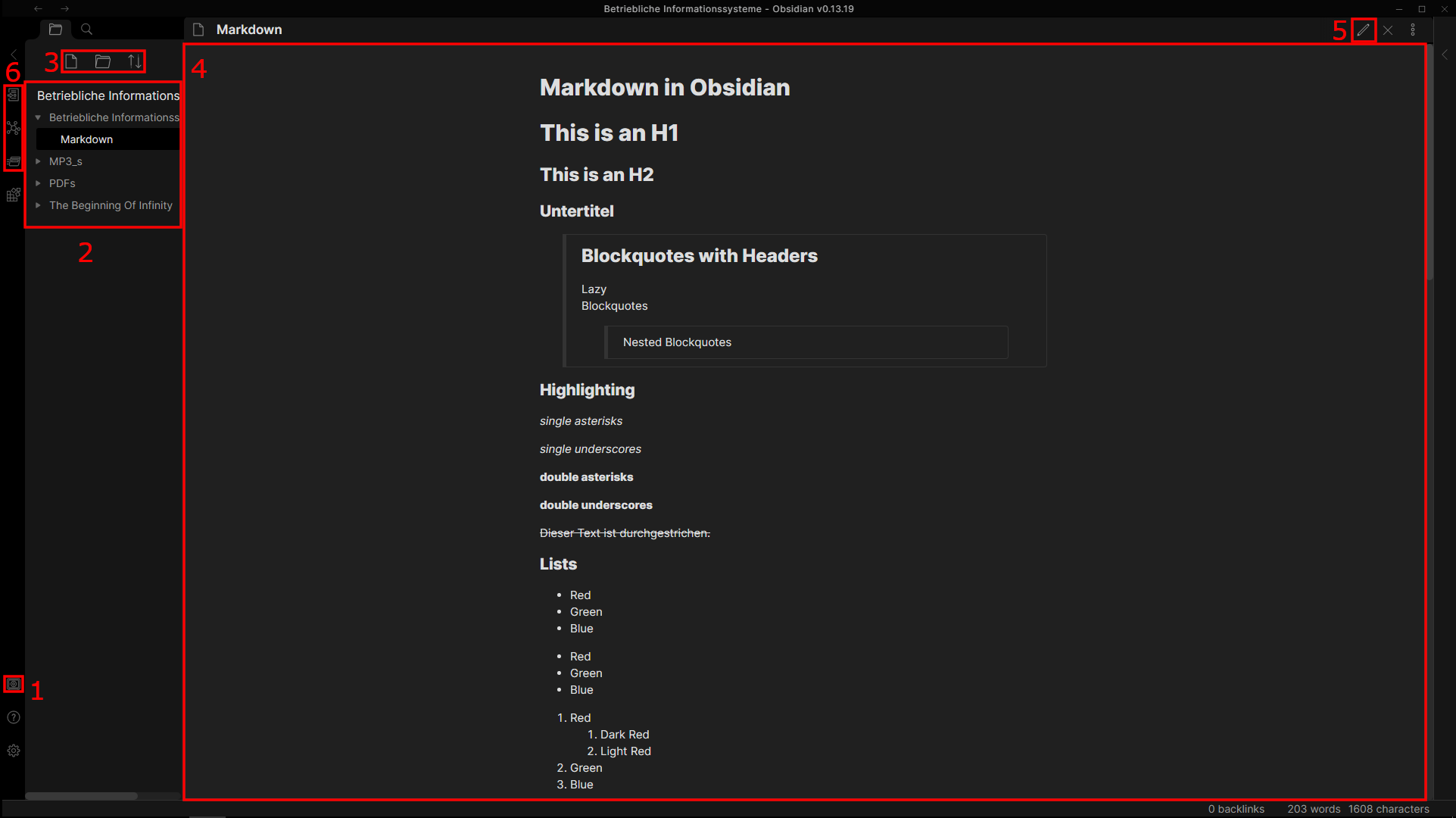
Wenn man Obsidian das erste Mal startet, verlangt das Programm, dass man einen neuen Vault anlegt. Das heißt Obsidian benötigt einen Ort, an welchem es alle zukünftigen Dateien ablegen kann. In der Regel ist das ein einfacher Ordner, der sich irgendwo auf dem lokalen Dateisystem befindet.
Umso eine Ordner anzulegen, klickt man unten links auf den Button mit der Nummer 1. Hier hat man drei Optionen. Entweder man öffnet einen bereits vorhanden Ordner als Vault oder man lässt von Obsidian einen neuen Ordner anlegen. Als letztes hat man die Möglichkeit einen Beispielvault zu öffnen, welcher bei der Installation von Obsidian angelegt wurde.
Nachdem man einen Vault geöffnet hat, bekommt man im linken Bereich mit der Nummer 2 eine Übersicht über aller Dateien, die sich in diesem Vault befinden. Wenn man einen neuen Vault erstellt hat, wird hier noch nichts angezeigt, bis man eine Datei in dem Vault angelegt hat.
Mit den Buttons im Bereich 3 kann man einen neuen Ordner oder eine neue Datei erstellen. Alternativ kann man hier auch die Sortierung für alle Dateien ändern. Beim Erstellen einer Datei wird immer eine Markdown Datei erstellt.
Möchte man einen anderen Dateityp integrieren, dann kann man das machen, indem man die Datei über den normalen Dateiexplorer in den passenden Ordner des Vaults kopiert.
Sobald man eine Datei aus der Übersicht anklickt, wird deren Inhalt in dem großen Bereich mit der Nummer 4 in der Mitte angezeigt.
Speziell für Markdown Dateien gibt es oben links noch den Button mit der Nummer 5. Hiermit kann man zwischen einen Bearbeitungs- und einem Vorschaumodus wechseln. Im Vorschaumodus bekommt man den formatierten Text zu sehen, der sich auch nicht verändern lässt. Wechselt man jedoch in den Bearbeitungsmodus sieht man den normalen Inhalt der Markdown Datei und kann diesen auch bearbeiten.
Mit dem Panel auf der linken Seite mit der Nummer 6 kann man zwischen den verschiedenen Ansichten in Obsidian wechseln. Die erste Ansicht ist die, die man in dem Bild zum User Interface sehen kann.
Die andere Ansicht ist eine Graphansicht. Ein Beispiel hierfür gibt es im Abschnitt zu der Beispielanwendung zu sehen. Hier werden alle Dateien aus dem Vault als einzelne Punkte dargestellt. Die einzelnen Punkte werden verbunden, wenn in einer Datei ein Verweis zu einer anderen Datei vorhanden ist. So bilden alle Dateien dann einen Graph. Dieser Graph lässt sich nach bestimmten Worten oder Tags durchsuchen. Wenn man einen der Punkte anklickt, wird die dazugehörige Datei in der Vorschau angezeigt.
Anwendungsbeispiel
Für einen besseren Eindruck, wie die Anwendung arbeitet wenn eine größere Anzahl an Inhalten integriert ist, haben wir ein eigenes Anwendungsbeispiel erdacht.
Um möglichst einfach einen großen Wissensgraphen zu erzeugen, haben wir uns entschieden alle PDF-Dateien der Fakultät Informatik&Medien zu crawlen. Damit wir nicht zu jeder PDF das Markdown-File manuell erstellen mussten, wurde ein Python-Skript geschrieben. Das Skript erstellt anhand des PDF-Dateinamens automatisch eine Datei mit Tags, Links und einer Verknüpfung zum PDF.
PDF-Crawl
Zum Crawlen haben wir das Kommandozeilenprogramm wget verwendet. Mit dem folgenden Befehl lassen sich alle PDFs der FIM-Homepage herunterladen.
wget –no-clobber –random-wait -r -p -nd -A pdf -e robots=off https://fim.htwk-leipzig.de/
–no-clobber verhindert, dass wget eine Datei herunterlädt, wenn sie eine bereits vorhandene Datei überschreiben würde.
–random-wait bewirkt, dass die Zeit zwischen den Anfragen zwischen 0,5 und 1,5 Sekunden variiert.
-r aktiviert rekursives Abrufen
-p veranlasst Wget, alle Dateien herunterzuladen, die für die korrekte Anzeige einer bestimmten HTML-Seite notwendig sind.
-nd be, werden alle Dateien im aktuellen Verzeichnis gespeichert, ohne dass sie geklammert werden.
-A pdf sorgt dafür, dass nur PDF-Dateien runtergeladen werden.
-e robots=off wird verwendet damit die robots.txt Datei ignoriert wird (manche Web-Hosts blockieren Crawler mit robots.txt Datei)
Der Befehl hat im Dezember 2021 900MB an PDFs von der IMN-Homepage heruntergeladen.
Python-Skript
Das Skript ist unter https://github.com/ssd-ls-a/htwk_pdf_knowledge_base zu finden.
Zum Ausführen gibt es Hinweise in der README.md.
Als Parameter werden die Pfade zu dem Ordner der PDFs und dem Ordner, in den die Markdown-Dateien gespeichert werden sollen, übergeben.
Um in die erzeugten Dateien automatisch Links und Tags zu schreiben, werden die Dateinamen der PDFs in einzelne Bestandteile zerlegt. Im Anschluss wird geprüft, ob diese Bestandteile als Keys eines Dictionarys vorhanden sind und wenn ja, wird der zugehörige Wert in die Markdowndatei als Link oder Tag geschrieben. In dem Dictionary sind Abkürzungen wie zum Beispiel INM (=Informatik Master) enthalten. Zusätzlich werden reguläre Ausdrücke verwendet um Jahreszahlen zu identifizieren und diese ebenfalls als Link in die Datei zu schreiben.
Darstellung in Obsidian
Auf den folgenden Bildern ist der aus den erzeugten Markdown-Dateien erstellte Wissensgraph zu sehen.

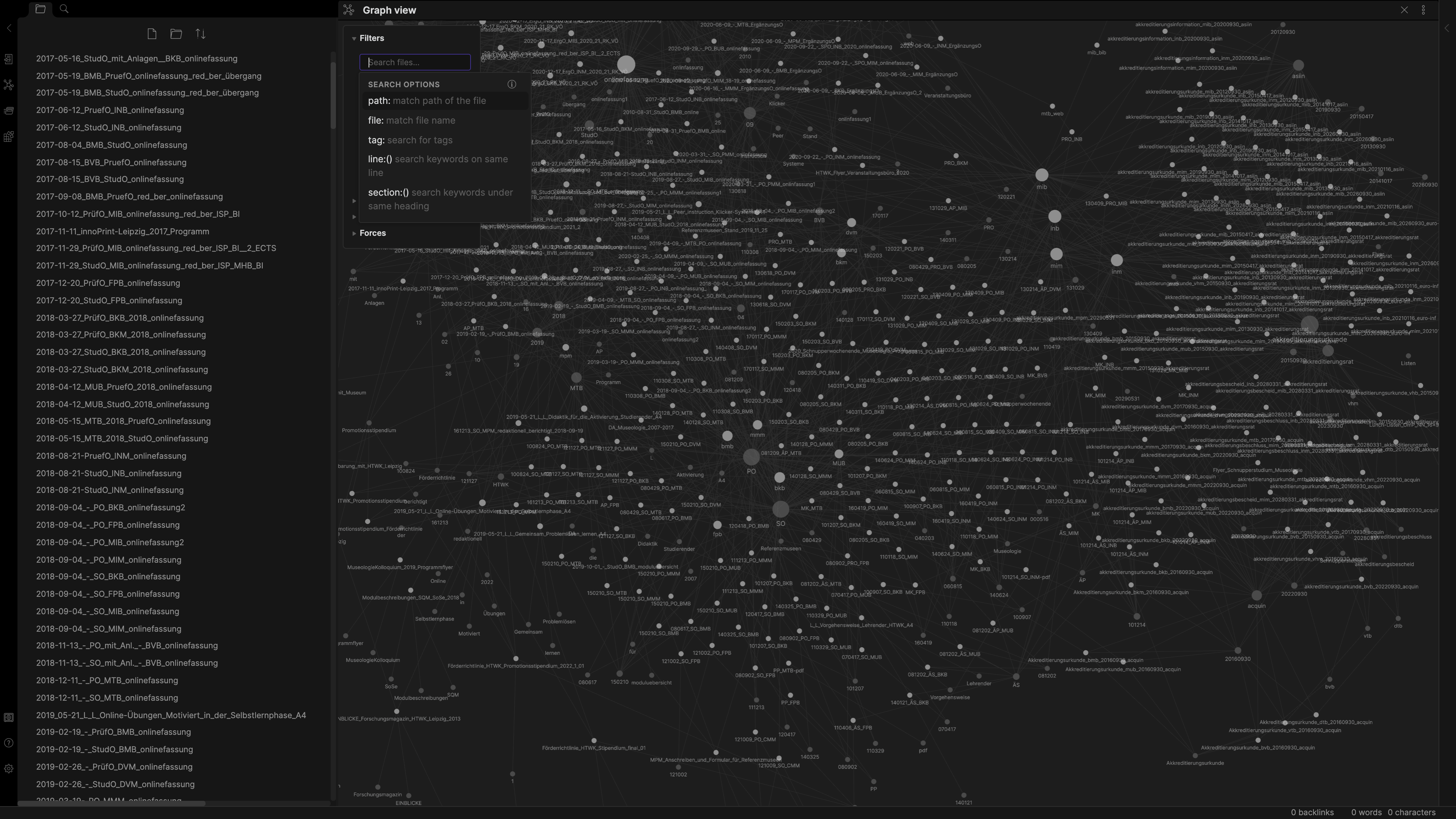
Hier wurde nach dem Link ‚IMN‘ gefiltert:

Weiterführende Links
Foliensatz zum zugehörigen Vortrag
Obsidian Hauptseite
Github Anwendungsbeispiel
wget manual page
Eine Antwort auf “Obsidian”