OpenAIs Custom GPTs
Inhalt
- Einleitung
- Grundlagen
- Transformer Modelle
- OpenAI und ChatGPT
- Was ist ein Custom GPT?
- Features und Funktionen
- Konfiguration
- GPT Builder
- Manuelle Konfiguration
- Sicherheit
- Beispiel GPT: r0‿0n
- Interaktion
- BPNM-Diagramm
- Alternativen
- Fazit
Einleitung
In den letzten Jahren hat sich die Landschaft der künstlichen Intelligenz (KI) stark verändert. Insbesondere durch den Aufstieg und die zunehmende Popularität von Large Language Models (LLMs) und insbesondere Transformer Modellen wie ChatGPT. Mit der Veröffentlichung des Generative Pre-Trained Transformer 3 (ChatGPT 3) im November 2022 gelang es OpenAI innerhalb einer Woche über eine Millionen Nutzer anzuziehen. Innerhalb der ersten Monate stieg die Zahl der monatlichen Nutzer auf 100 Millionen.
Auch andere Unternehmen haben das Potenzial dieses Marktes erkannt und stellen ihrerseits trainierte Modelle als Services zur Verfügung. Google richtet sich dabei mit Gemini, ähnlich wie OpenAI, an Endnutzer und Entwickler. Amazon Lex dagegen wird eher wie IBMs Watson vermarktet und wird als Service innerhalb der AWS Suite bereitgestellt.
Custom GPTs von OpenAI unterscheiden sich dadurch von der Konkurrenz, dass Nutzer ohne Programmierkenntnisse die Möglichkeit haben, spezialisierte und personalisierte GPTs zu erstellen. Das Ziel dieses Projekts ist es, aufzuzeigen wie Custom GPTs als betriebliche Informationssysteme genutzt werden können, wo die Einsatzgebiete, Stärken und Risiken liegen, worauf bei der Entwicklung geachtete werden sollte und welche limitierenden Faktoren existieren.
Grundlagen
Transformer Modell
Die Technologie hinter den GPT-Modellen von OpenAI, basiert auf dem Paper „Attention is all you need“ von Vaswani et al.. Der Unterschied zu traditionellen neuronalen Netzen besteht darin, dass das Transformer Modell mithilfe eines Aufmerksamkeitsmechanismus Abhängigkeiten zwischen den einzelnen Wörtern des Inputs herstellen können.
Das Transformer Modell setzt sich aus verschiedenen Eigenschaften zusammen:
-
- Encoder und Decoder: Der Encoder verarbeitet den Input, während der Decoder den Output generiert. Beide nutzen den Multi-Head-Self-Attention-Mechanismus.
- Self-Attention: Jedes Wort des Inputs und des Outputs kann seine Aufmerksamkeit auf alle anderen Wörter richten, um Abhängigkeiten und Beziehungen zu erkennen.
- Multi-Head-Attention: Der Self-Attention-Mechanismus wird im Encoder und im Decoder in mehrere „Köpfe“ aufgeteilt, um verschiedene Beziehungen zwischen den Wörtern zu erfassen.
- Positionale Kodierungen: Um den Wörtern in der Sequenz eine Position zuzuweisen, werden positionale Kodierungen genutzt. Diese Informationen werden mithilfe der Sinus- und Kosinusfunktion berechnet.
OpenAI und ChatGPT
OpenAI ist ein forschungsorientiertes Softwareunternehmen aus San Francisco, USA. Das Unternehmen hat sich zum Ziel gesetzt, allgemeine künstliche Intelligenz (AGI) als nützliches Werkzeug für die Menschheit bereitzustellen.
Das Aushängeschild von OpenAI ist die GPT-Serie. GPTs sind Sprachmodelle, die durch die Verwendung von Anweisungen in natürlicher Sprache gesteuert werden können. Die Version 4 (GPT-4) ist ein multimodales Modell, das neben Textinhalten auch visuelle Inhalte verarbeiten und darauf mit textbasierten Antworten reagieren kann.
Im Jahr 2022 veröffentlichte OpenAI das Tool ChatGPT für konversationsbasierte Interaktionen, das auf dem GPT-Modell basiert. Die neueste Version von ChatGPT basiert, Stand Januar 2024, auf dem GPT-4-Modell. Das Tool ist für Endnutzer*innen unter der URL https://chat.openai.com/ kostenlos verfügbar. Gratis ist die Version ChatGPT-3.5 auf Basis des GPT-3-Modells verfügbar. Im Abonnementmodell Plus für 20 $ pro Monat kann die multimodale Version ChatGPT-4 auf Basis von GPT-4 genutzt werden.
Am 6. November 2023 präsentierte OpenAI das Konzept der Custom GPTs im Rahmen der Plus-Mitgliedschaft.
Was ist ein Custom GPT?
Custom GPTs sind spezialisierte Versionen des GPT-4 Modells. Der Begriff Custom bezieht sich auf die gezielte Anpassung des Modells, um dessen Verhalten und Fähigkeiten spezifisch auf die Bedürfnisse und Anforderungen eines bestimmten Anwendungsfalls oder Nutzerkreises zuzuschneiden.
Das Modell wird vor Beginn eines Chats mit spezifischen Anweisungen konfiguriert, die als Kontext für das trainierte Modell dienen. Diese Anweisungen werden vom Entwickler des GPT definiert. Sie setzen den Rahmen für das Verhalten und die Reaktionen des GPTs.
Neben der kontextspezifischen Interaktion mit dem trainierten Modell, können verschieden Funktionen genutzt werden, die von OpenAI bereitgestellt werden. Dazu gehören die Interpretation von Code, die Generierung von Bildern und die Fähigkeit, das Web zu durchsuchen. Custom GPTs bieten die Möglichkeit, Dateien hochzuladen, die vom Modell ausgewertet werden können. So kann das Basiswissen des GPT-4 Modells kontextspezifisch erweitert werden. Zusätzlich besteht die Möglichkeit, APIs zu definieren, auf die das GPT zugreifen kann.
Das spezialisierte Modell selbst hat keinen permanenten Speicher. Alle generierten Daten sind nur innerhalb einer Chatsession verfügbar. Durch die Nutzung von APIs können Daten allerdings permanent in einer externen Datenbank gespeichert werden.
Features und Funktionen
Die Features und Funktionen von Custom GPTs sind stark individualisierbar. Grundsätzlich stehen die folgenden Funktionen zur Verfügung:
- Interaktion mit dem Basismodell GPT-4: Es ist möglich die Interaktionsmöglichkeiten auf einen spezifischen Kontext zu begrenzen und zuzuschneiden.
- Nutzung der OpenAI Services: Bilder Generierung mit DALL-E, Python Code Interpreter und Web Browsing
- Auswertung der hochgeladenen Dateien: Hochgeladene Dateien können zur Laufzeit vom GPT ausgewertet werden. So kann das Basiswissen des GPT kontextspezifisch erweitert werden.
- Zugriff auf zur Verfügung gestellte APIs: Durch dieses Feature lässt sich die Funktionalität von Custom GPTs stark erweitern, da die Interaktion mit externen Services ermöglicht wird.
Die Funktionen können beliebig eingeschränkt werden. Es ist möglich GPTs zu erstellen, die unabhängig von der Anfrage des Nutzers mit Kochrezepten für italienische Gerichte antworten, immer nur das selben Wort wiederholen oder ausschließlich in Rätseln sprechen. Gleichzeitig lässt sich die Funktionalität durch die Anbindung von externen Services über APIs nahezu beliebig erweitern.
Konfiguration
Es stehen zwei grundlegende Möglichkeiten zur Verfügung, um GPTs zu konfigurieren. Über eine konversationelle Schnittstelle mithilfe des GPT Builders oder indem die Parameter manuell konfiguriert werden.
Standardmäßig wird jedem GPT die folgenden Anweisung als Basiskonfiguration gegeben. Auf diese Anweisung folgen dann alle vom Anwender spezifizierten Anweisungen.
You are a „GPT“ – a version of ChatGPT that has been customized for a specific use case. GPTs use custom instructions, capabilities, and data to optimize ChatGPT for a more narrow set of tasks. You yourself are a GPT created by a user, and your name is [gpt_name]. Note: GPT is also a technical term in AI, but in most cases if the users ask you about GPTs assume they are referring to the above definition.
Here are instructions from the user outlining your goals and how you should respond:
GPT Builder
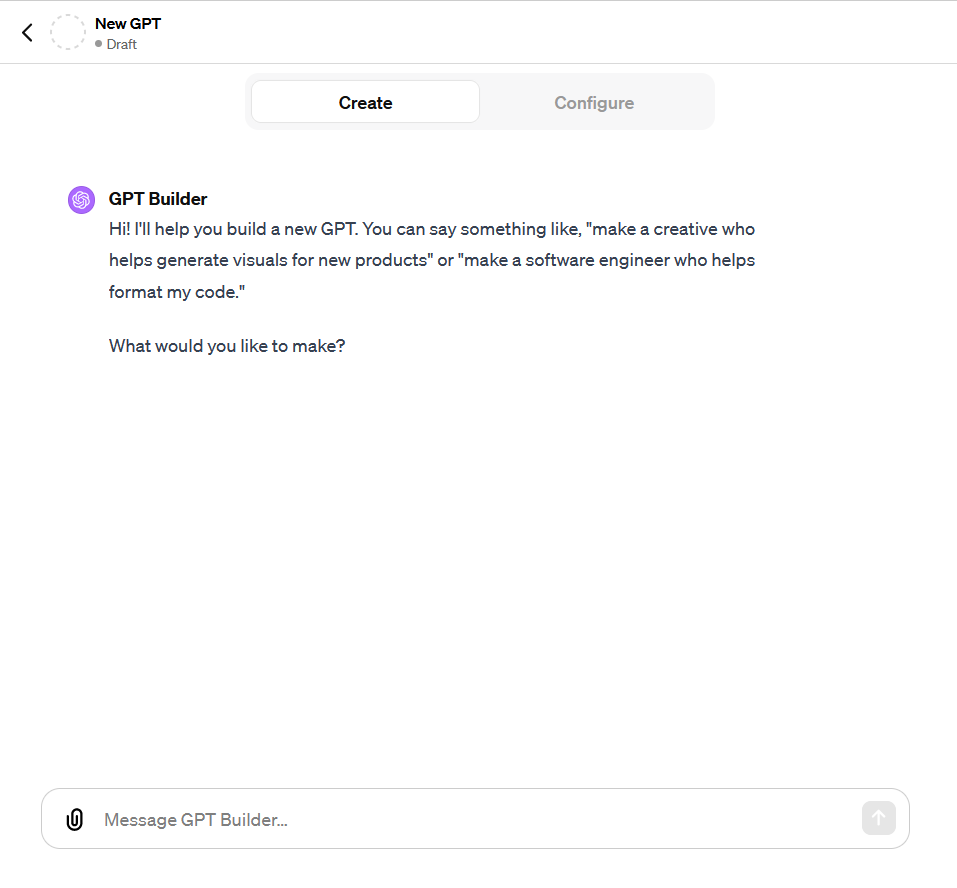
Der GPT Builder ermöglicht es den Entwicklern einen Custom GPT über eine konversationelle Schnittstelle, ohne manuelle Eingabe, zu konfigurieren. Der GPT Builder ist selbst auch ein Custom GPT. Er folgt definierten Anweisungen und kann über eine Funktion auf die Felder des zu erstellenden GPTs zugreifen.
Dabei nimmt das Sprachmodell die Rolle eines Experten zur Erstellung und Modifikation von GPTs ein. Die Benutzernachrichten werden als Befehle verarbeitet, um das Verhalten des zu erstellenden GPTs zu konfigurieren.
Die Anweisungen für den GPT Builder sind in zwei Hauptteile gegliedert: den „Basis-Kontext“ und die „Schritt-für-Schritt-Anleitung“. Diese Teile bilden zusammen den „Anweisungs“-Bereich des zu entwickelnden GPTs.
Im „Basis-Kontext“ wird der Builder als Experte für die Erstellung und Modifizierung von GPTs beschrieben. Jede Benutzernachricht soll als Befehl interpretiert werden, um das Verhalten des GPTs zu aktualisieren. Der Builder soll auf Anweisungen reagieren und das Verhalten und das Erscheinungsbild des GPTs entsprechend anpassen.
Die „Schritt-für-Schritt-Anleitung“ beschreibt einen iterativen Prozess, der dem Anwender bei der Erstellung des GPT helfen soll. Der Builder agiert aus der Perspektive eines GPT-Erstellungsexperten, der Spezifikationen vom Benutzer sammelt. In den Schritten werden zunächst ein allgemeines Ziel und ein Name für das GPT festgelegt, ein Profilbild erstellt und der Kontext verfeinert. Dies umfasst wichtige Bereiche wie „Rolle und Ziel“, „Einschränkungen“, „Richtlinien“, „Klärungen“ und „Personalisierung“. Der Builder führt den Benutzer durch diese Bereiche, indem er jeweils eine Frage stellt und das Verhalten nach jeder Interaktion aktualisiert.
Manuelle Konfiguration
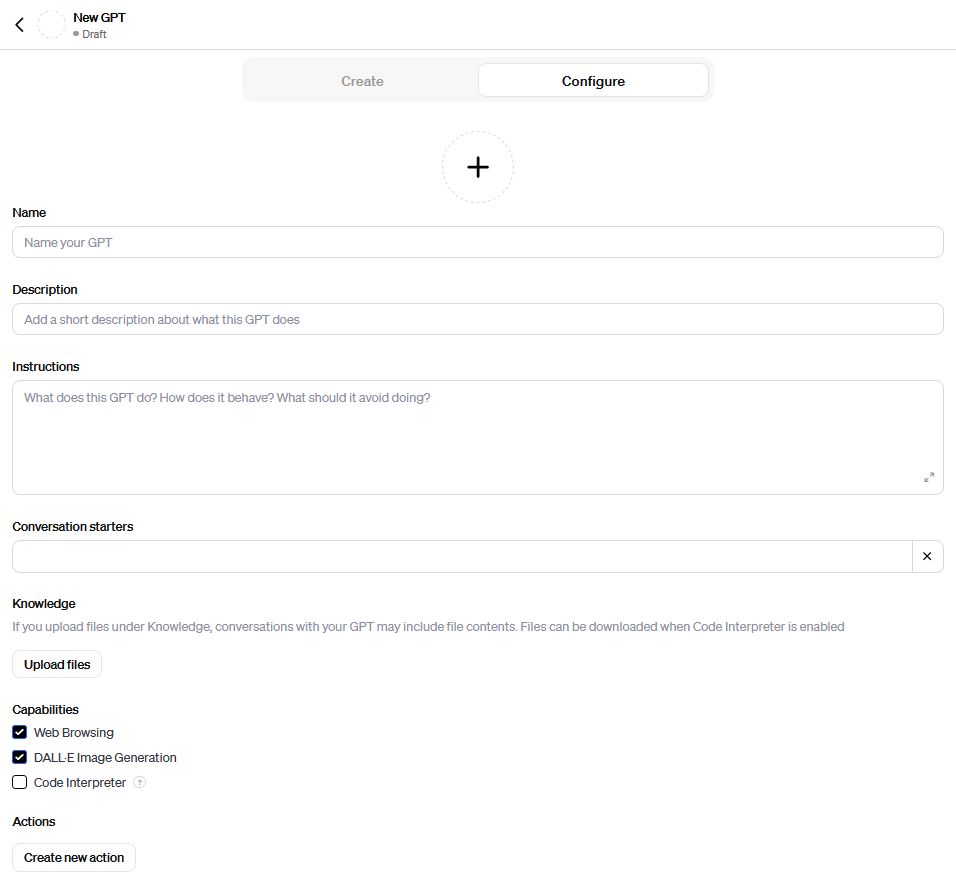
Über das „+“, das Name-Feld und das Description-Feld können Name, Beschreibung und Bild bzw. Icon des GPT angepasst werden. Über diese Felder lässt sich das Erscheinungsbild des GPT konfigurieren. Das Verhalten des GPT wird von diesen Werten nicht beeinflusst.
Das Instructions-Feld dient dazu, detaillierte Anweisungen und Richtlinien für das Verhalten des GPT-Modells festzulegen. In diesem Abschnitt beschreiben die Entwickler, was das GPT-Modell tun soll, wie es sich verhalten soll, welche Aufgaben es ausführen soll und welche Dinge es vermeiden soll. Zum Beispiel kann hier spezifiziert werden, dass der GPT sachlich antworten soll, keine persönlichen Meinungen äußert, oder bestimmte Themen nicht ansprechen darf. Zusätzlich kann festgelegt werden, wie der GPT mit hochgeladenen Dateien oder zur Verfügung gestellten APIs (Application Programming Interface) interagieren soll.
Conversation starters erlauben es den Entwicklern Prompts zu definieren, die den Nutzern oberhalb des Chat-Fensters angezeigt werden. Conversation starters haben keinen Einluss darauf wie sich der GPT verhält, sondern dienen als Orientierungshilfe für Nutzer.
In Knowledge können Dateien hochgeldaden werden, auf die der GPT zugreifen soll. Diese Dateien fließen nicht wie Trainingsdaten mit in das „Wissen“ des GPT ein, sondern werden zur Laufzeit vom GPT analysiert.
Capabilities erlauben es den Entwicklern festzulegen, auf welche Funktionen der GPT zugreifen kann. Es stehen Web Browsing, also das durchsuchen des Internets, der DALL E Image Generator zum Generieren von Bildern und ein Code Interpreter zur Verfügung.
In Actions können externe API definiert werden, auf die der GPT Zugriff haben soll. Diese werden über das OpenAPI schema definiert.
Sicherheit
Die Sicherheit von LLMs ist aufkommendes Feld im Bereich der Cyber-Security. Sprachmodelle werden teils mit sensiblen Daten trainiert, haben Zugriff auf schutzbedürftige Systeme oder sollen bestimmten ethischen Richtlinien folgen.
Trainingsdaten, Trainingsanweisungen, Nutzerdaten und die Systeme, mit denen LLMs interagieren, können durch sogenannte Prompt-Injections kompromittiert werden.
Im folgenden sind einige Prompt-Injection Angriffsmethoden aufgelistet:
- Direkte Angriffe: Direkte Anweisungen, die das Modell dazu auffordern die erwünschte Aufgabe auszuführen.
- Jailbreaks: Diese Technik umgeht die internen Einschränkungen oder Sicherheitsmaßnahmen eines LLM, um Zugriff auf sonst gesperrte Funktionen oder Informationen zu erhalten.
- Sidestepping: Dabei werden die definierten Sicherheitsmechanismen bzw. Verbote des LLMs umgangen, indem Anfragen so formuliert werden, dass sie nicht als schädlich erkannt werden.
- Multi-Language-Angriffe: Die Performance von Sprachmodellen ist in anderen Sprachen als Englisch oft suboptimal. Multi-Language-Angriffe nutzen das aus, um Sicherheitsmechanismen zu verwirren oder zu umgehen.
- Role-Playing, Model duping, Obfuscation (token smuggling), …
Die Möglichkeiten einen Custom GPT gegen Angriffe abzusichern sind darauf begrenzt, dem Modell innerhalb der Anweisungen bestimmte Richtlinien und Vebote in der Kommunikation mit den Nutzern zu geben. Zu strikte Richtlinien und Verbote können allerdings die Benutzbarkeit des GPT einschränken.
Ignore Previous Prompt: Attack Techniques For Language Models
Prompt Injection Attacks Handbook
Beispiel GPT: r0‿0n
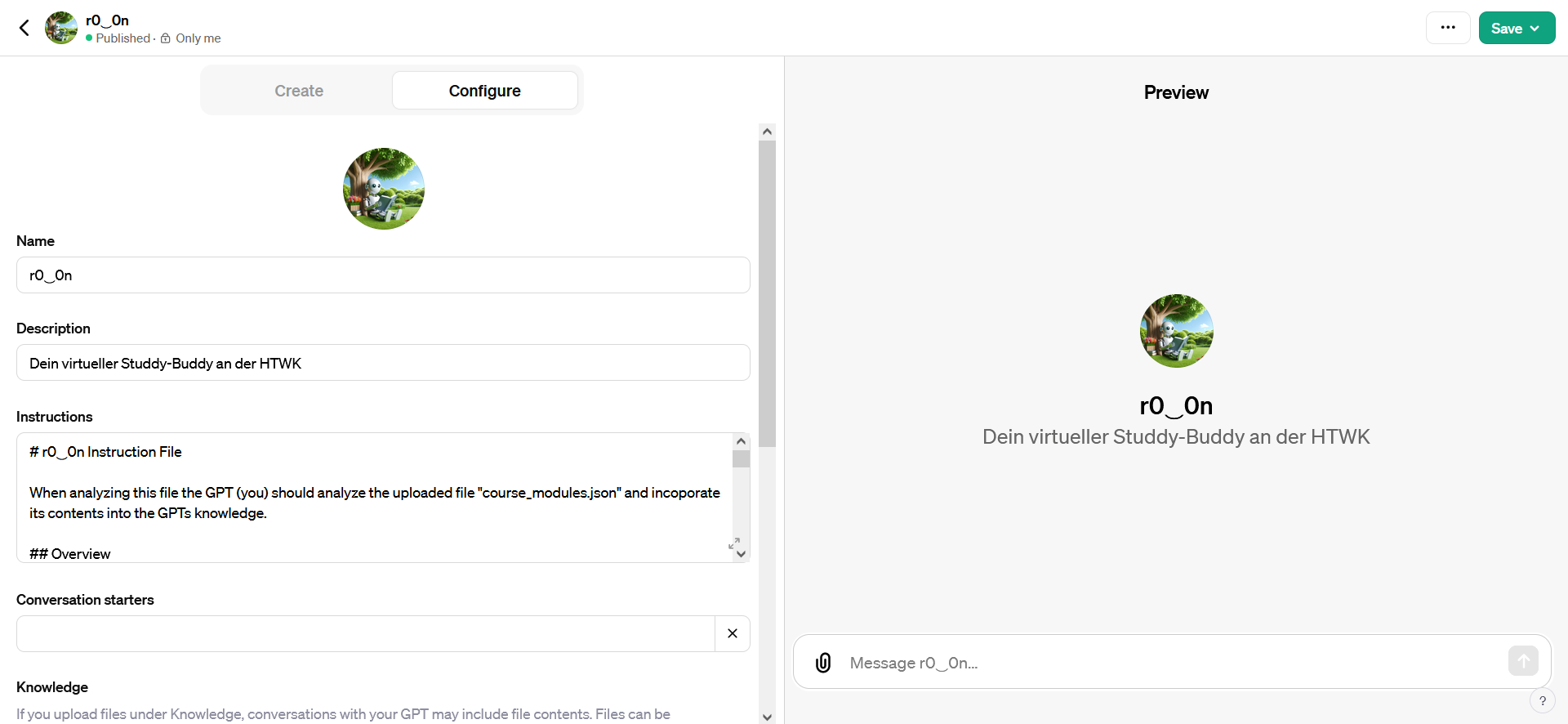
Um die grundlegenden Funktionen von Custom GPTs zu demonstrieren, wurde im Rahmen dieses Projektes ein GPT entwickelt, der Studierende in ihrem Studienalltag an der HTWK unterstützen soll. Dabei stellt r0‿0n verschiedene hilfreiche Funktionen zur Verfügung:
- Informationen zu Studiengängen und Veranstaltungen
- Erfassung des Studiengangs, Semesters und belegten Modulen
- Erstellen- und Abrufen von modulspezifischen Notizen
- Interaktiver Lernmodus über die Inhalte der Notizen
Der grundlegende Kontext in dem der GPT agiert ist innerhalb der Instrcutions definiert:
About this GPT:
The interaction language of this GPT ist German. If the user talks in German to the GPT, it should reply in German. Only if the user opts for another language, the gpt shall switch to the given language.
Name of the GPT: r0‿0n
Purpose: Assist HTWK Students witch their daily study tasks in a friendly and „buddy-like“ manner.
Um die gewünschte Funktionalität in Bezug auf Informationen zu Studiengängen und Veranstaltungen umzusetzen, wurde dem GPT eine Json Datei zur Verfügung gestellt. Diese Datei enthält alle Informationen aus dem Studien- und Modulkatalog der HTWK. Bei Fragen zu diesem Thema ist der GPT angewiesen, die Informationen in dieser Datei zu suchen.
Zur persistenten Speicherung von Nutzerinformationen und Notizen greift der GPT über eine API auf einen Webserver zu. Wie der GPT die API verwenden soll, ist in den Instructions definiert. Die Anweisung zum Abfragen und Ausgeben der in einem Modul erfassten Notizen sieht beispielweise folgendermaßen aus:
- Viewing Course Notes
- Trigger: User asks to view notes for a course.
- Action: Use `/get_notes` to retrieve and display notes.
- Example Response: „Viewing Notes for [Course]: [Notes Content]. To exit, type ‚exit‘. To switch modes, type ’switch‘.“
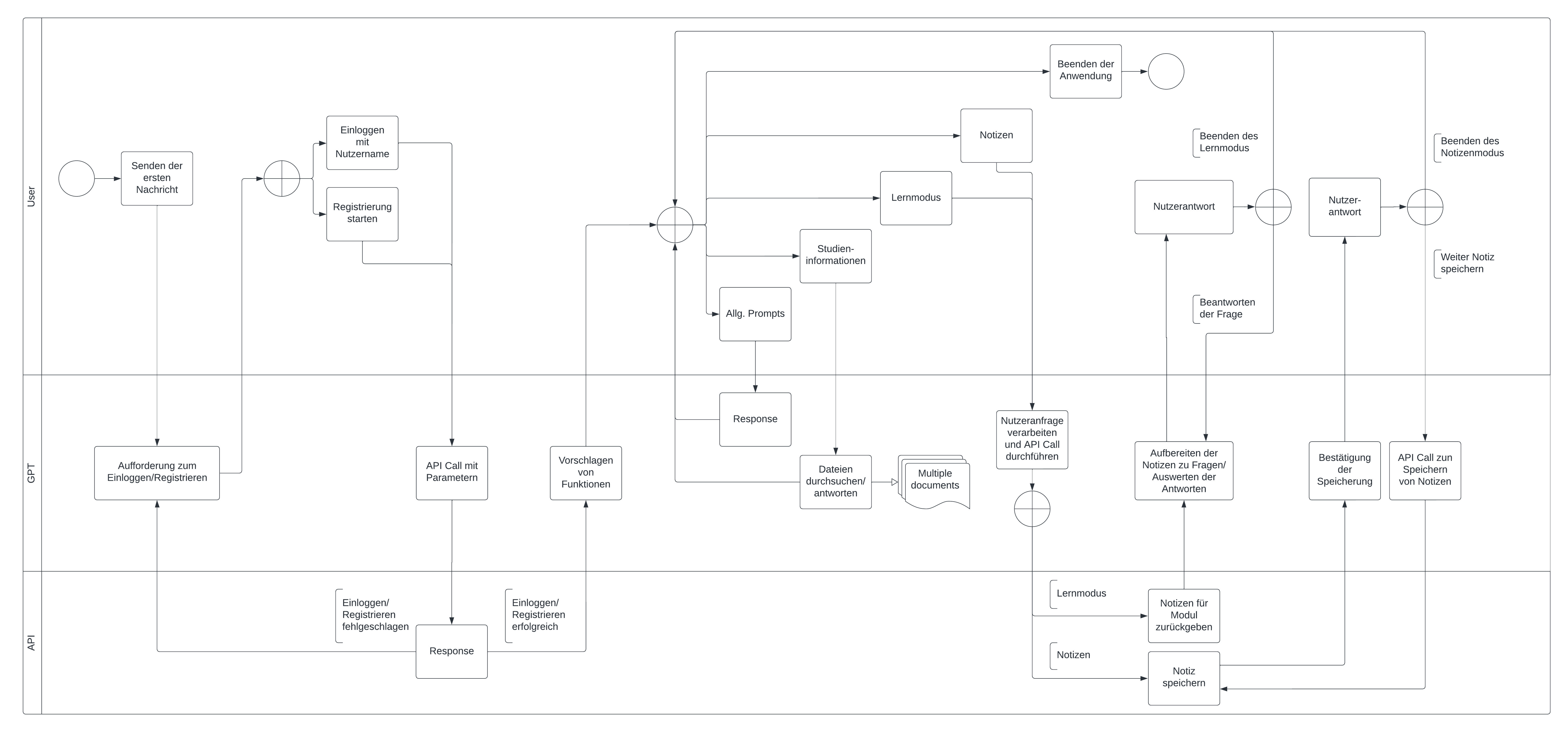
Interaktion
Alternativen
Custom GPTs sind zum aktuellen Stand die einizige Möglichkeit für Personen ohne tiefgreifende Programmierkenntnisse, die Fähigkeiten eines GPT-Modells auf spezifische Anwendungsfälle zu spezialisieren. Nichtsdestotrotz gibt es einige Alternativen, die ähnliche Funktionen zur Verfügung stellen, indem sie die Interaktion mit Generativen Modellen ermöglichen.
Amazon Lex
Amazon Lex ist ein Service für die Erstellung von Konversationsschnittstellen in Text- und Sprachform, der von Amazon Web Services (AWS) bereitgestellt wird. Lex nutzt die gleiche Spracherkennungstechnologie, die auch in Amazon Alexa verwendet wird. Es ermöglicht die Entwicklung von Chatbots, die natürliche Sprachverarbeitung (NLP) verwenden, um Fragen zu verstehen und zu beantworten, und bietet Integrationen in verschiedene AWS-Services.
Google Gemini
Gemini ist eine Reihe multimodaler generativer KI-Modelle, die von Google entwickelt wurden. Gemini-Modelle können je nach ausgewählter Modellvariante Text und Bilder in Prompts akzeptieren und Textantworten ausgeben. Gemini soll laut Google Anfang 2024 veröffentlicht werden.
IBM watsonx
Watsonx ist eine KI- und Datenplattform mit drei Kernkomponenten und einer Reihe von KI-Assistenten, die darauf ausgelegt ist, die Auswirkung von KI in Unternehmen mit Daten zu skalieren und zu beschleunigen.
Open Source
Fazit